摘要
1) 一句话总结 本文介绍了一种名为“退一步提示法”(Step-Back Prompting)的提示工程技术,通过引导大语言模型(LLM)对复杂问题进行高层次的抽象思考,促使其自行生成高质量的上下文信息,从而大幅提升模型推理和解答的准确性。
2) 关键要点
- 方法来源:该方法源自论文《Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models》,核心思想是遇到复杂问题时先“退一步”,从更宏观、抽象的角度进行审视。
- 核心机制:包含“抽象”和“推理”两个步骤。首先针对原问题提出一个更高层次的抽象问题(如询问背后的原理),然后将该抽象问题的答案与原问题结合,作为更丰富的上下文提交给LLM进行最终解答。
- 理科应用示例:在解答复杂的物理计算题时,先引导模型回答“该问题背后的物理原理是什么”(如引出理想气体状态方程),随后模型便能轻松套用公式得出正确结果。
- 文科应用示例:在回答特定时间点的历史细节问题时,先让模型输出相关人物“完整的教育历史”,再基于此宏观信息回答具体细节,可避免模型直接回答时容易出现的错误。
- 与RAG(检索增强生成)的异同:两者都是通过补充相关上下文来提高回答准确率;但退一步提示法不需要借助外部数据库,而是通过正确的提示词直接激发LLM从其内部庞大的知识库中“检索”有效信息。
- 与CoT(思维链)的异同:CoT依赖于将复杂问题拆解为若干步骤,如果问题难以分解,CoT可能失效;退一步提示法不拆解问题,而是从更高层次补充上下文信息。
- 行业共性发现:结合近期多篇关于机器翻译、类比推理的论文可以看出,不借助外部工具、仅通过特定提示法(如先解释后翻译、先找类似问题、先直译后意译)激发LLM自行生成高质量上下文,是提升模型输出质量的重要通用策略。
正文
中文里面经常会说:站得高看得远,要有大局观。英文里面有个词叫 Step back,字面意思是后退一步,有时候开会的时候常用,当讨论陷入僵局,就有人说:“Let’s step back”,意思是我们后退一步,站在更高的层次来看问题,不要纠缠在细节的讨论中。
最近的一篇论文:《Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models》(中文翻译《退一步,看得更远:通过抽象引发大语言模型中的推理 [译] 》),就是讲的在使用 LLM 处理复杂任务或问题时,不是直接去解决问题,而是先退后一步,从更高层次、更抽象的角度来审视问题,引导语言模型进行抽象思考,从而激发或引导模型进行更为准确和有效的推理。
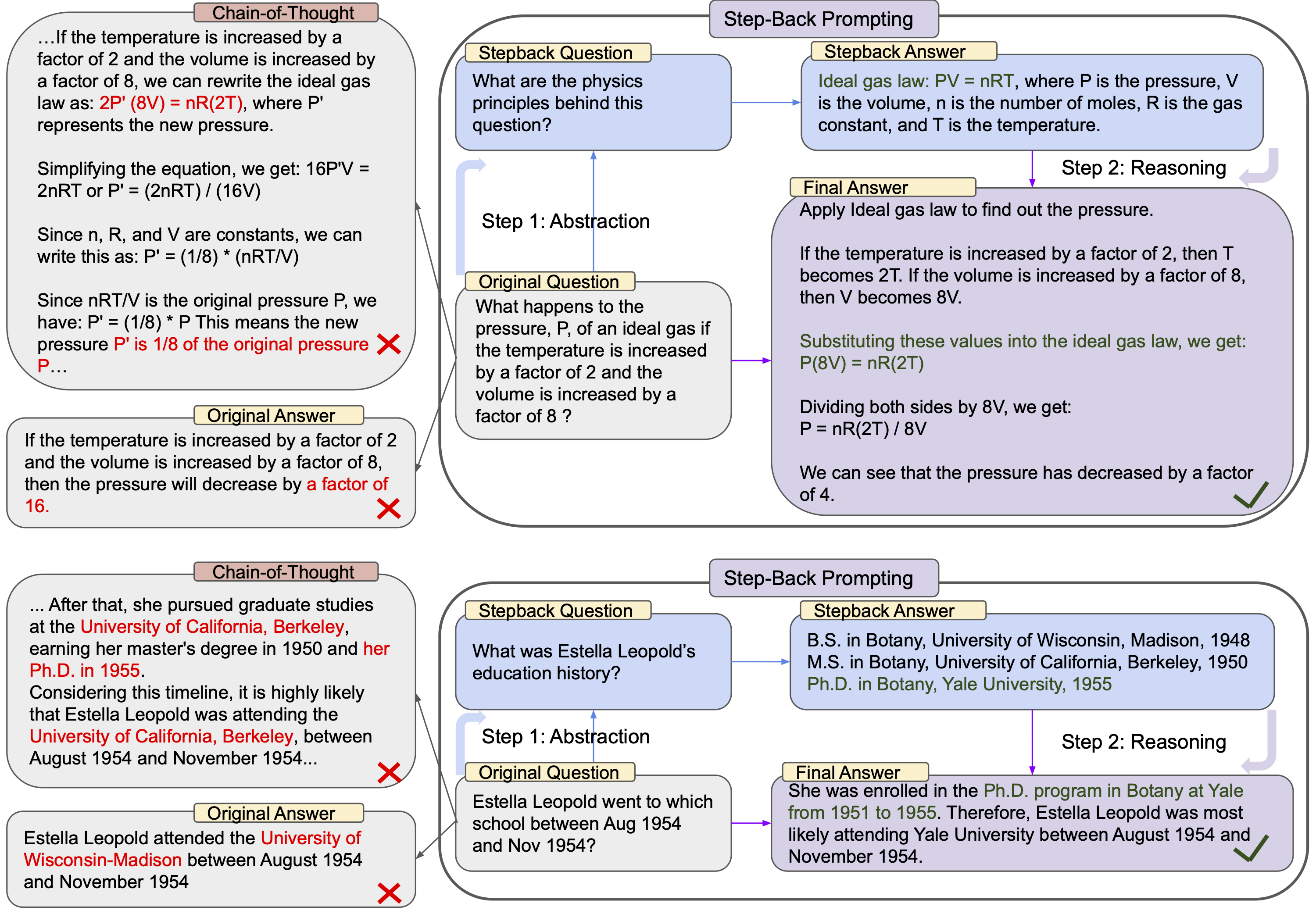
一个名为“Step-Back Prompting”的两步抽象和推理过程,通过概念和原则的引导来实现
这种方法受到了人类处理复杂问题时喜欢退后一步、从更宏观的角度审视问题的启发。
比如我们在中学学物理,遇到复杂的物理问题,会思考问题背后的物理原理是什么,搞清楚了背后的物理原理,直到相应的物理定理,解决起来就很容易。就像一个物理题目:“如果理想气体的温度增加了 2 倍,体积增加了 8 倍,那么压力 P 会发生什么变化?”,如果我们直接解答,可能没什么头绪,但如果老师提示我们对这个问题抽象一下,提出一个新的问题:“这个问题背后的物理原理是什么?”,那么我们就会想到理想气体状态方程,然后套用公式就可以很容易的解决这个问题了。这里老师的提示,就类似于论文中提出的对问题抽象,引出一个“退一步”的问题。最后将原始问题,加上“退一步”的问题和答案放在一起,就得到了更多的有价值的上下文信息,这些信息可以帮助 LLM 更好的理解原始问题,从而更好的解决原始问题。
图片中的另一个例子是一个历史问题:“Estella Leopold 在 1954 年 8 月至 1954 年 11 月期间去了哪所学校?”,这类问题对于 LLM 来说很容易答错,但是如果后退一步,站在更高层次对问题进行抽象,提出一个新的问题:“Estella Leopold 的教育历史是怎样的?”,那 LLM 可以先将 Estella Leopold 都列出来,然后将这些信息和原始问题放在一起,那么对于 LLM 来说就可以很容易给出正确的答案。
第二个例子其实很像检索增强生成 (RAG),那些文档问答就是类似的机制,当用户提一个问题,按照问题从数据库里面把相关问题检索出来,然后将检索出来的信息和原始问题放在一起作为上下文提交 LLM,这样 LLM 就可以很容易的给出正确的答案。只不过对于第二个问题,由于 LLM 本身就有一个庞大的知识库,完全不需要借助外部的数据库,只要采用正确的方法激发,就可以让它自己从自己的知识库里面检索出有效的信息,从而得到高质量的结果。
这个后退一步提示法,和传统的思考链(CoT)又有所不同,思考链是将复杂的问题拆分成若干步骤,这依赖于人类对问题分解,或者让 LLM 去对问题进行分解,但是对于上面这两个例子,并不好对问题进行分解,就像图中的例子,如果问题不能很好的分解成合理的步骤,CoT 也得不到正确的结果。而后退一步提示法,本质上不是对问题分解,而是从另一个角度,从更高的层次上,提出一个相关的问题,能为原始的问题补充有效的上下文信息,当有了这些有效的上下文信息,LLM 就可以很容易的得到正确的结果。
如果我们综合最近的其他几篇论文一起看,就会发现要让 LLM 能得到高质量的问答,和原始问题相关的高质量上下文信息是非常重要的,最好是不需要借助外部工具,直接通过特定的方法“激发”LLM 自己去生成高质量的上下文信息,比如:
- 《退一步,看得更远:通过抽象引发大语言模型中的推理 [译]》 这个是让 LLM 对问题抽象,从更高层次提供更多信息,借助这些信息帮助理解原始问题。
- 《深入分析 GPTs 在机器翻译中的上下文学习》 这篇论文则是讲在对文本翻译前,先不直接翻译,用目标语言解释要翻译的问题,而解释的文本就是高质量的上下文,能有效提升翻译质量
- 《大语言模型的类比推理能力》 这篇论文则是让大语言模型先从自己的知识库找出原始问题类似的问题和答案,作为上下文的一部分,可以极大提升回答问题的准确性。
还有我以前提出的《一个简单的 Prompt 大幅提升 ChatGPT 翻译质量,告别“机翻感”》,也是类似的思路,让 LLM 先对文本直译,直译的内容作为上下文的一部分,这样将原始文本和直译文本放在一起,再去意译,得到的质量就会更高。
相关文档
- 一个简单的 Prompt 大幅提升 ChatGPT 翻译质量,告别“机翻感”;关联理由:引用;说明:正文明确引用这篇文章作为“先生成高质量上下文再完成任务”的同类实践案例。
- 一种新的 Prompt 方法——“类推提示法”;关联理由:延伸思考;说明:两文都强调先让 LLM 生成与原问题相关的中间信息,再用这些信息提升最终解答准确性。
- 一个“退后一步 Step back”的提示词技巧;关联理由:版本演进;说明:同一 Step-Back 思路从论文解读延伸到后续更偏实操的提示词技巧文章。