摘要
1) 一句话总结 NitroGen是一个开源的视觉-动作基础模型,通过从4万小时的互联网游戏视频中自动提取动作数据进行大规模预训练,为通用游戏智能体提供了跨游戏的开箱即用能力和高效的迁移微调表现。
2) 核心要点
- 三大核心组件:包含一个多游戏基础智能体(支持零样本游玩与微调)、一个通用模拟器(通过Gymnasium API封装控制任意商业游戏),以及一个互联网规模的视频-动作数据集。
- 超大规模数据集:精选了40,000小时的公开游戏视频,覆盖超过1,000款游戏(其中15款游戏数据量超过1,000小时),主要类型包括动作RPG(34.9%)和平台游戏(18.4%)。
- 自动动作提取管道:通过识别视频画面中的“手柄覆盖层(input overlays)”,利用关键点匹配(SIFT和XFeat)定位手柄,并使用混合分类-分割网络准确预测摇杆位置和按键状态。
- 高提取精度:动作提取质量高,摇杆位置的R²相关性得分平均为0.84,按键帧准确率平均高达0.96。
- 模型架构与规模:使用流匹配(flow-matching)GR00T架构,在整个数据集上通过行为克隆训练了一个包含5亿(500M)参数的单一视觉-动作策略模型。
- 开箱即用的泛化能力:无需额外微调,该模型即可在不同视觉风格(3D、2D俯视、2D横版)和多种游戏类型中执行非平凡(non-trivial)任务。
- 显著的迁移微调提升:在未见过的游戏上,相比于同等算力和数据下从头训练的模型,NitroGen微调后的任务完成率平均相对提升10%;在低数据量(30小时)场景下,相对提升最高可达52%。
- 全面开源:研究团队将公开发布该数据集、评估套件以及模型权重,以降低新环境下的智能体训练门槛。
3) 风险与局限性(基于原文明确提及)
- 数据噪声问题:用于预训练的互联网视频数据集被明确指出存在高度噪点(very noisy internet dataset)。
- 数据提取挑战:视频中的手柄覆盖层在控制器类型(如Xbox、PlayStation)、透明度以及视频压缩引入的视觉伪影方面存在巨大差异,给动作数据的准确提取带来了显著挑战。
正文
Loïc Magne1 *, Anas Awadalla1 2 *, Guanzhi Wang1 3 * †
Yinzhen Xu1, Joshua Belofsky4, Fengyuan Hu1, Joohwan Kim1,
Ludwig Schmidt2, Georgia Gkioxari3, Jan Kautz1,
Yisong Yue3 †, Yejin Choi1 2 †, Yuke Zhu1 5 †, Linxi “Jim” Fan1 †
1 NVIDIA,2 斯坦福大学,3 加州理工学院,4 芝加哥大学,5 德克萨斯大学奥斯汀分校
摘要
我们介绍了 NitroGen,这是一个为通用游戏智能体设计的视觉-动作基础模型,它在超过 1,000 款游戏的 40,000 小时游戏视频上进行了训练。我们整合了三个关键要素:1) 一个互联网规模的视频-动作数据集,通过从公开的游戏视频中自动提取玩家动作构建而成;2) 一个多游戏基准环境,能够衡量跨游戏泛化能力;以及 3) 一个统一的视觉-动作策略,通过大规模行为克隆训练而成。NitroGen 在不同领域均展现出强大的能力,包括 3D 动作游戏中的战斗交锋、2D 平台跳跃游戏中的高精度控制,以及在程序化生成世界中的探索。它能有效地迁移到未见过的游戏中,与从头开始训练的模型相比,任务成功率实现了高达 52% 的相对提升。我们开源了数据集、评估套件和模型权重,以推动通用具身智能体的研究。
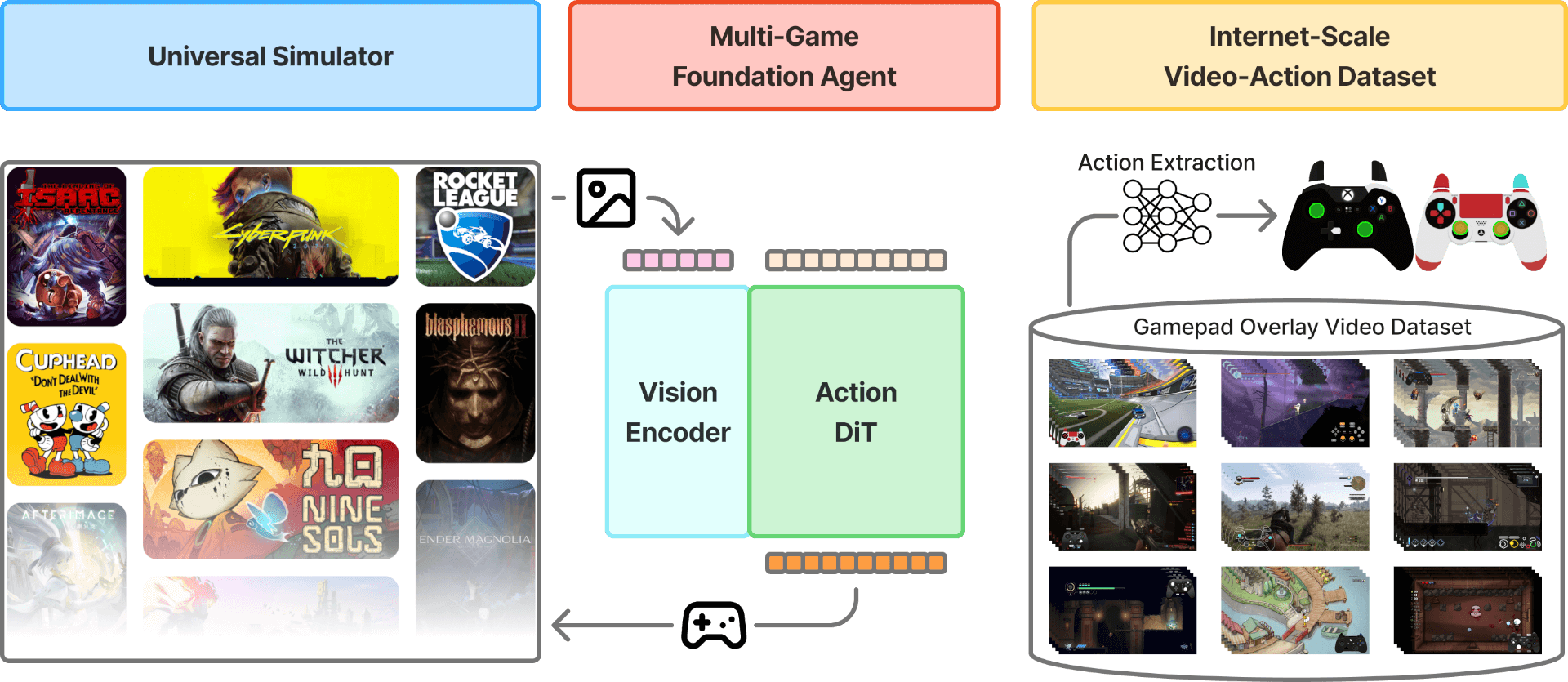
概览。 NitroGen 由三个主要组件构成:(1) 多游戏基础智能体(中)——一个通用的视觉-动作模型,接收游戏观察结果并生成手柄动作,从而在多款游戏中实现零样本游玩,并作为在新游戏上进行微调的基础;(2) 通用模拟器(左)——一个环境包装器,允许通过 Gymnasium API 控制任何商业游戏;以及 (3) 互联网规模数据集(右)——最大且最多样化的开源游戏数据集,从 40,000 小时的公开游戏视频中整理而成,涵盖超过 1,000 款游戏并带有提取的动作标签。
引言
构建能够在未知环境中运行的通用具身智能体,一直被认为是人工智能研究的圣杯。尽管计算机视觉和大型语言模型(LLM)已经通过在互联网数据上进行大规模预训练实现了这种泛化,但具身人工智能(Embodied AI)领域由于缺乏大规模、多样化且带有标签的动作数据集,其相应进展受到了阻碍。视频游戏为推进具身人工智能提供了一个理想的领域,因为它们提供了视觉丰富的环境以及跨越广泛复杂度和时间跨度的任务。然而,以往的方法面临着巨大的局限性。基于 LLM 的方法要么利用 (1) 手工制作的编程 API 来暴露内部游戏状态并控制智能体,要么利用 (2) 复杂的感知模块来进行文本信息提取和目标检测。它们能够解决复杂的任务,但需要复杂的特定领域设计和微调。强化学习在《星际争霸 II》和《Dota 2》等个别游戏中取得了超越人类的表现,但这些智能体适用范围狭窄、训练成本高昂,并且依赖于专门的模拟器,而这些模拟器很少能用于任意游戏。基于像素观察的行为克隆方法依赖于昂贵的由众包人员收集的演示数据,由于数据收集成本过高,训练被限制在少数几款游戏中。
互联网规模的多游戏视频-动作数据集
视频-动作数据集流水线概览。 我们从屏幕显示中提取动作,这些显示实时展示了玩家的手柄动作;这被称为“输入覆盖层(input overlays)”。(左)数据集整理。 我们收集了显示“手柄覆盖层”的公开视频。这些覆盖层的多样性带来了重大挑战,因为不同内容创作者使用的手柄在控制器类型(例如 Xbox、PlayStation 或其他)、透明度级别以及视频压缩引入的视觉伪影方面差异巨大。(右)动作提取。 对于每个收集到的视频,我们通过采样 25 帧并使用 SIFT 和 XFeat 特征与一组精心整理的模板进行关键点匹配来定位手柄。我们使用模板匹配结果从每个视频中定位并裁剪出手柄区域。然后,我们训练了一个混合分类-分割网络,从裁剪出的控制器图像中预测摇杆位置和按键状态,从而实现对玩家输入的准确重建。
动作质量控制
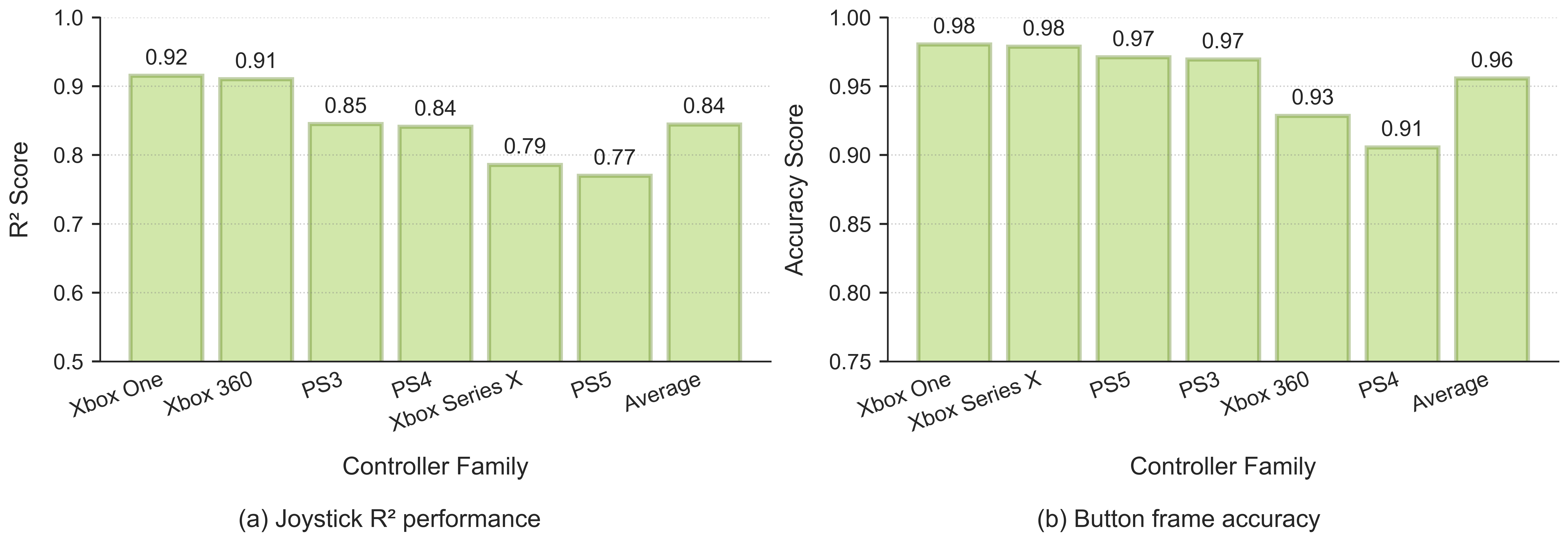
动作提取质量。 我们通过将不同控制器系列的性能与真实(ground-truth)数据进行比较,验证了动作提取流水线的正确性。(a) 展示了摇杆 R² 相关性得分(左右摇杆的平均值),总体平均值为 0.84。(b) 展示了按键帧准确率,总体平均值为 0.96。
数据集分析

NitroGen 数据集在不同游戏和类型中的分布。 经过过滤后,该数据集包含涵盖 1,000 多款游戏的 40,000 小时游戏视频。(a) 每款游戏的时长显示了广泛的覆盖范围,其中 846 款游戏拥有超过 1 小时的数据,91 款游戏超过 100 小时,15 款游戏每款超过 1,000 小时。(b) 游戏类型分布显示,动作角色扮演(Action-RPG)游戏最为常见(占总时长的 34.9%),其次是平台跳跃(Platformer,18.4%)和动作冒险(Action-Adventure,9.2%)游戏,其余分布在各种不同的类型中。
实验
开箱即用的多游戏能力
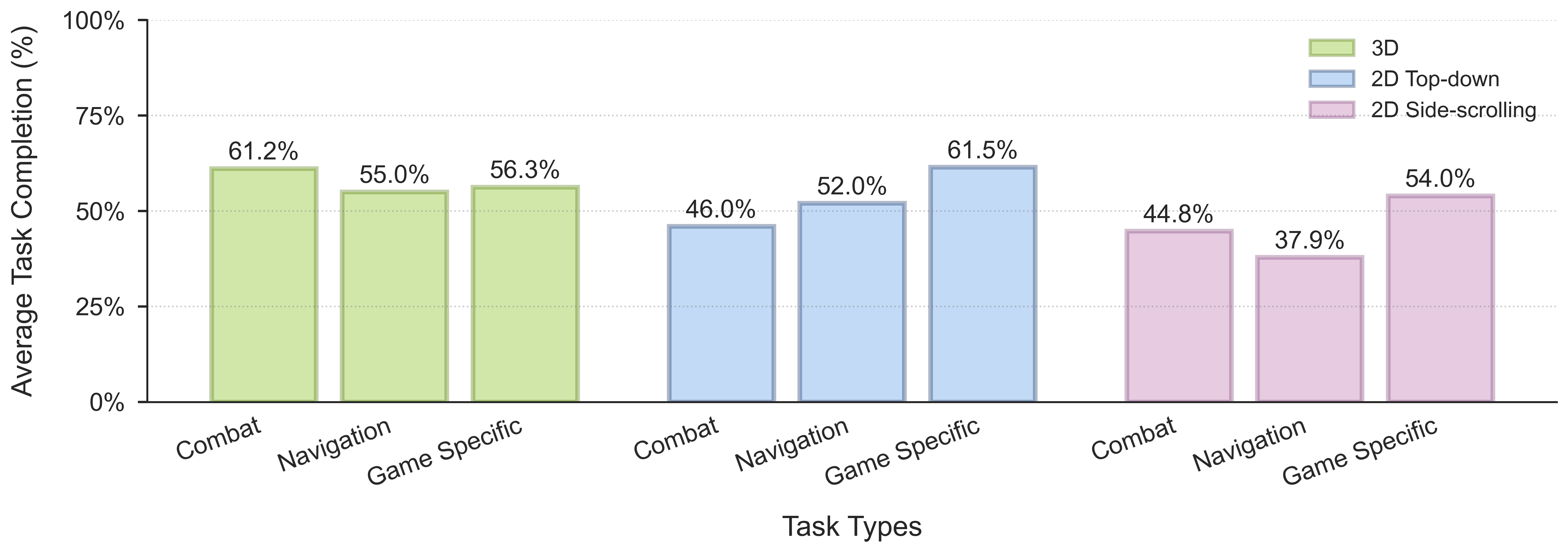
NitroGen 500M 在不同游戏中的预训练结果。 我们使用流匹配(flow-matching)GR00T 架构在整个 NitroGen 数据集上训练了一个单一的 5 亿(500M)参数模型。我们在行为克隆预训练之后对其进行了评估。对于每款游戏,我们测量了 3 个任务的平均任务完成率,每个任务进行 5 次 rollout(运行)。在没有进一步微调的情况下,尽管是在非常嘈杂的互联网数据集上进行训练的,NitroGen 仍能够在具有不同视觉风格(3D、2D 俯视、2D 横版卷轴)和类型(平台跳跃、动作角色扮演、类Rogue 等)的游戏中执行复杂的任务。
在未见游戏上的预训练迁移
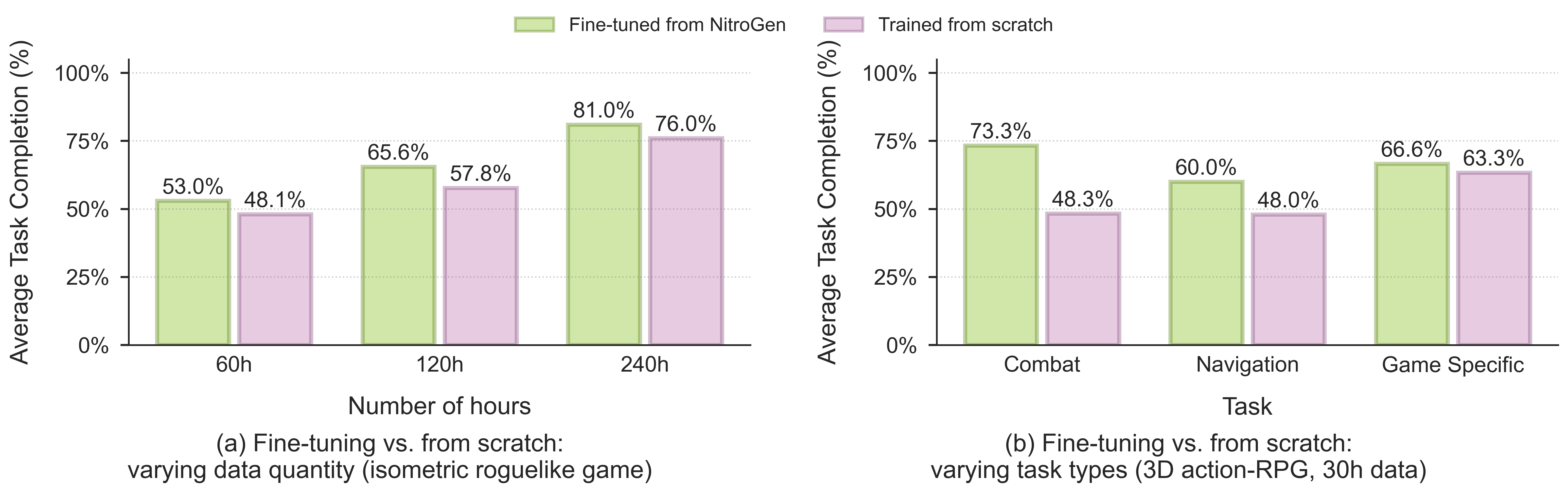
训练后实验。 NitroGen 预训练提升了下游智能体在未见环境中的表现。我们在上述数据集上对 NitroGen 进行预训练,并留出(hold out)一款游戏不参与训练。然后,我们在留出的游戏上对预训练的检查点进行微调,并将结果与使用相同架构、数据和计算预算从头开始训练的模型进行比较。(a) 当改变数据量时,任务完成率随数据集大小成比例增长,并且微调在任务完成率上平均实现了 10% 的相对提升。(b) 当在低数据量区间(30 小时)下改变任务类型时,微调在任务完成率上实现了高达 52% 的相对提升。
结论
在这项工作中,我们介绍了 NitroGen,这是一种扩大视频游戏智能体基础预训练规模的方法,并展示了互联网预训练如何产生通用的策略。我们利用一种新的公开数据源构建了一个互联网规模的视频-动作数据集,并通过成功训练多游戏策略,在经验上证明了其有效性。NitroGen 在微调实验中展现出了良好的泛化潜力。通过降低在新环境中训练智能体的门槛,NitroGen 成为开发更强大、更通用智能体的起点。
团队
 Loïc Magne *
Loïc Magne *
 Anas Awadalla *
Anas Awadalla *
 Guanzhi Wang * †
Guanzhi Wang * †
 Yinzhen Xu
Yinzhen Xu
 Joshua Belofsky
Joshua Belofsky
 Fengyuan Hu
Fengyuan Hu
 Joohwan Kim
Joohwan Kim
 Ludwig Schmidt
Ludwig Schmidt
 Georgia Gkioxari
Georgia Gkioxari
 Jan Kautz
Jan Kautz
 Yisong Yue †
Yisong Yue †
 Yejin Choi †
Yejin Choi †
 Yuke Zhu †
Yuke Zhu †
 Linxi “Jim” Fan †
Linxi “Jim” Fan †
- 共同主导 † 共同指导
BibTeX
@misc{magne2026nitrogen,
title={NitroGen: An Open Foundation Model for Generalist Gaming Agents},
author={Loïc Magne and Anas Awadalla and Guanzhi Wang and Yinzhen Xu and Joshua Belofsky and Fengyuan Hu and Joohwan Kim and Ludwig Schmidt and Georgia Gkioxari and Jan Kautz and Yisong Yue and Yejin Choi and Yuke Zhu and Linxi "Jim" Fan},
year={2026},
eprint={2601.02427},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2601.02427},
}