摘要
1) 一句话总结 本文介绍了如何结合思维链(CoT)、输出中间结果与 Function Calling 技术,使用大语言模型(如 GPT-3.5)低成本且高效地解决英中字幕翻译时多句合并与时间戳对齐的难题。
2) 关键要点
- 核心痛点:英译中字幕常出现多句英文合并为一句中文的情况,导致翻译结果与原始时间戳难以直接对齐,手工调整工作量大。
- 成本优化:使用 GPT-4 翻译半小时视频成本约 1 美元;改用 GPT-3.5 配合 Function Calling 及人工二次校对,可大幅降低成本且基本可用。
- 三步 Prompt 策略 (CoT):
- 将带有时间戳的输入数组合并为完整段落进行整体翻译(忽略 JSON 结构和时间戳)。
- 按标点符号将翻译结果重新拆分为中文短句。
- 将拆分后的中文短句与原始英文输入项(时间戳)重新对应。
- 输出中间结果:在处理复杂任务时,必须让模型输出中间步骤的结果(如完整翻译段落
fullTranslatedContent),以保证最终推理和对齐效果最佳。 - Function Calling 格式化:通过定义明确的 JSON 数据结构,强制模型输出易于程序解析的格式,同时可隐藏不需要让用户看到的中间结果。
- 工程化建议:明确区分 LLM 与传统程序的任务边界,解析和二次处理应交由程序完成,避免让 LLM 处理所有事务。
3) 风险与不足
- GPT-3.5 上下文长度限制:GPT-3.5 输入内容不能太长,单次处理 10-20 条字幕较为合适,过长会导致输出结果质量下降。
- GPT-4 成本高昂:虽然 GPT-4 单次处理 50 条字幕毫无压力,但使用成本过于昂贵。
- LLM 输出不稳定性:大语言模型生成的结果不够稳定,且存在较高成本,不能完全依赖其完成所有端到端的处理工作。
正文
一周过去了,现在是时候公布这题答案了,这道 Prompt 思考题 基本上是过去几道思考的集大成了。
这道题目来源于我日常的应用场景,因为我经常会翻译一些字幕,必不可少的要借助 GPT 来帮我完成,这样我只需要二次校对就可以节约很多工作。但是字幕翻译远比我想象的复杂,因为英文原文和中文不是一一对应的关系,通常多个英文字幕在翻译时会被合并成成一个中文,也很难原样拆分回去,所以我需要将翻译后的结果和原始的英文对应起来,靠手工对应工作量还是不小。
另外我以前是用 GPT-4 做的,但是 GPT-4 价格实在太贵了,按照我这种用法,翻译个半小时的视频就要 1 美元左右的成本。所以最近在 Function Calling 推出后,我尝试改用 GPT-3.5 来做,虽然不如 GPT-4 好,但是配合二次校对,基本上可用了。
先回顾一下题目,题目的输入是一组英文字幕,带有时间戳,时间戳是唯一的。
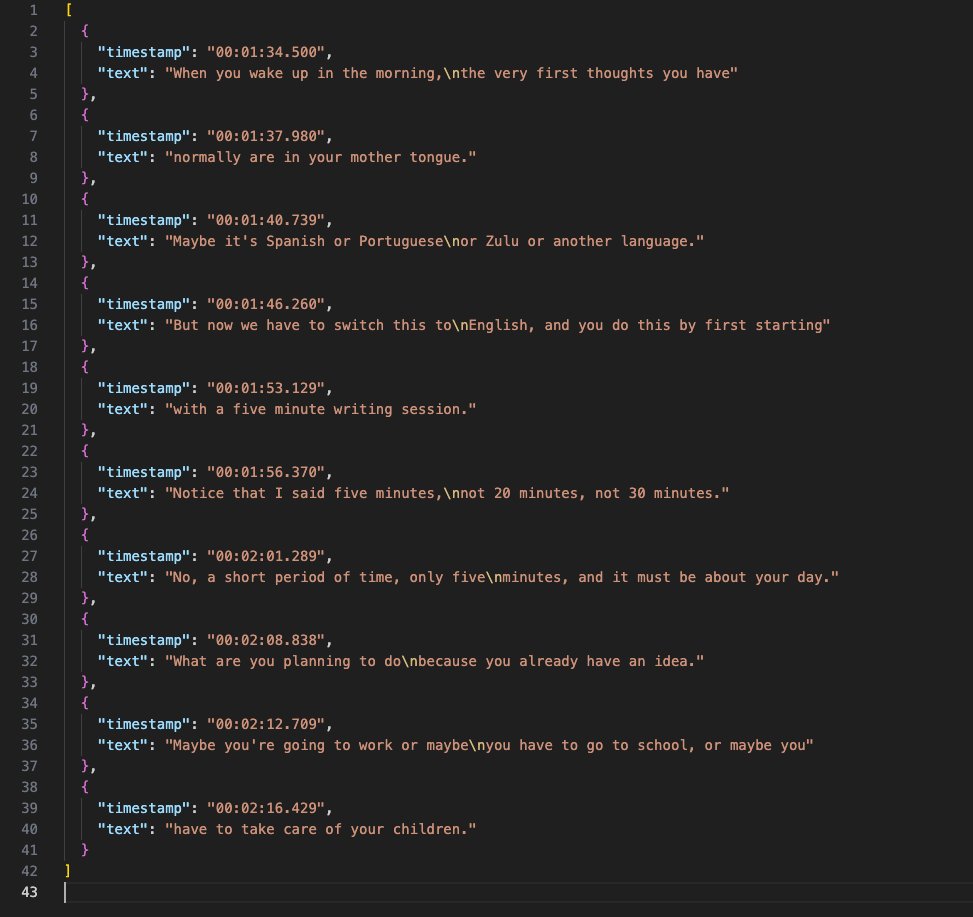
输出是翻译后的中文字幕,但是英文和中文不是一一对应的关系,多句英文在翻译时可能会被合并成一条中文。例如图一中第一条和第二条应该合并起来翻译成一个结果: “When you wake up in the morning, the very first thoughts you have” + “normally are in your mother tongue.” “当你早上醒来时,你通常会用母语思考。”

所以不仅要翻译,还要将翻译后重新断句的结果和原始输入对应起来。
这是一个非常典型的可以借助大语言模型的语言能力来解决自然语言问题的场景。
难点在于如何让大语言模型理解我们的要求,并且输出我们期望的格式!
对于这类问题,现在有三板斧可以用::
- CoT(Chain of Thought)
- 输出中间结果
- Function Calling
CoT 大部分人都不陌生,就是可以要做的事情分解成几个步骤,这样可以得到最好的推理效果。
但是仅仅在 Prompt 里面列出步骤是不够的,必须要配合输出中间结果,才能保证结果最佳,详情参考推文:https://twitter.com/dotey/status/1670116920815656961 所以我们必须输出必要的中间步骤结果。
对于输出结果,我们并不希望一些中间结果对用户可见,也希望结果容易被解析,JSON 格式无疑是最高的选择,在 Function Calling 之前,这很难,但是现在借助 Function Calling,可以轻松的让我们输出想要的 JSON 格式,并且也可以隐藏一些我们不想让用户看见的中间结果。有关 Function Calling 的应用也可以参考我以前出过的一道思考题: https://twitter.com/dotey/status/1671193519896109056
现在让我们把这三板斧组合起来使用:
首先要在 Prompt 指定角色和目的,然后分成三个步骤: 第一步:将输入的文字内容合并成一个完整的段落,作为一个整体翻译,相对一句一句翻译可以达到最好的翻译结果 第二步:将翻译好的结果按照标点符号重新拆分成小的句子 第三步:将拆分后的句子和原始输入对应起来
完整的 Prompt 参考如下:
You are a program responsible for translating subtitles.
Your task is to translate the subtitles into 简体中文,
maintain a conversational tone, avoid lengthy sentences,
and ignore fillers like “so”, “you know”, and “um”, etc.
the input is an array, each item includes timestamp and text.
Using the following steps:
Step 1: Translate the whole input array into 简体中文,ignore the json structure and the timestamp, only translate the text.
Step 2: Split the translated result into short sentences based on punctuation (e.g., periods, exclamation marks, question marks, etc.)
Step 3: Find out the input items that correspond to each translated sentence.
接下来还要借助 Function Calling 来输出我们想要的 JSON 格式,并且把中间结果也放到 JSON 中,所以可以先定义好想要的数据结构,这里我定义的数据结构是类似于这样的:
- 一个字符串 fullTranslatedContent,用来保存第一步完整的翻译结果
- 一个数组 translatedSentences 保存中文结果,对应的是第二步的结果
- 每个数组项中: 3.1 sentence 表示中文句子 3.2 relatedInputItems 是一个数组,和原始输入的英文的句子关键起来,也是 Prompt 中第三步的结果
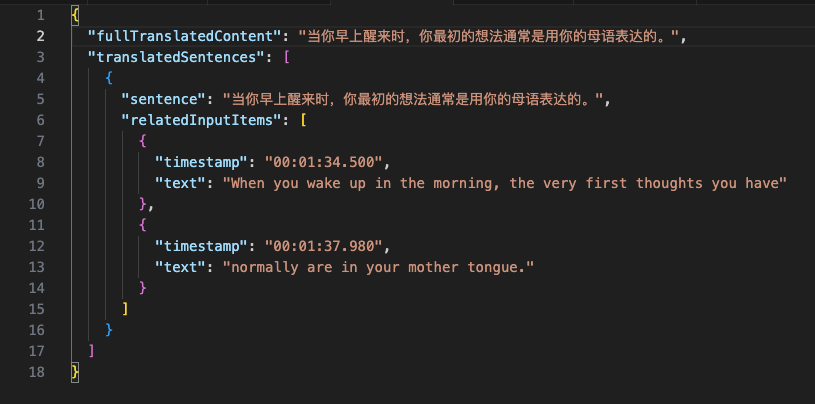
注意我在对属性名称命名时,名字比较长,但是比较容易理解是什么内容,这会在生成结果时有一点帮助。更详细的内容可以参考配图以及下面的函数定义:
{
name: functionName,
description: “format translated result”,
parameters: {
type: “object”,
properties: {
fullTranslatedContent: {
type: “string”,
description: “The translated input content”,
},
translatedSentences: {
type: “array”,
description:
“The splitted translated sentences, 1 translated sentence corresponds to 1 or more input items”,
items: {
type: “object”,
properties: {
sentence: {
type: “string”,
description: “A short and atomic translated sentence”,
},
relatedInputItems: {
type: “array”,
description:
“Related input items, 1 translated sentence corresponds to 1 or more input items”,
items: {
type: “object”,
properties: {
timestamp: {
type: “number”,
},
text: {
type: “string”,
},
},
},
},
},
required: [“sentence”, “relatedInputItems”],
},
},
},
required: [“fullTranslatedContent”, “translatedSentences”],
},
}
按照这种方式,基本上 GPT-3.5 也可能得到不错的结果,而且价钱也很便宜。但是注意对于 3.5 的话,输入内容不能太长,如果太长的话结果不会太好。我实际测试下来 10-20 条比较合适,GPT-4 的话,50 条都没什么问题,但是价钱很贵!
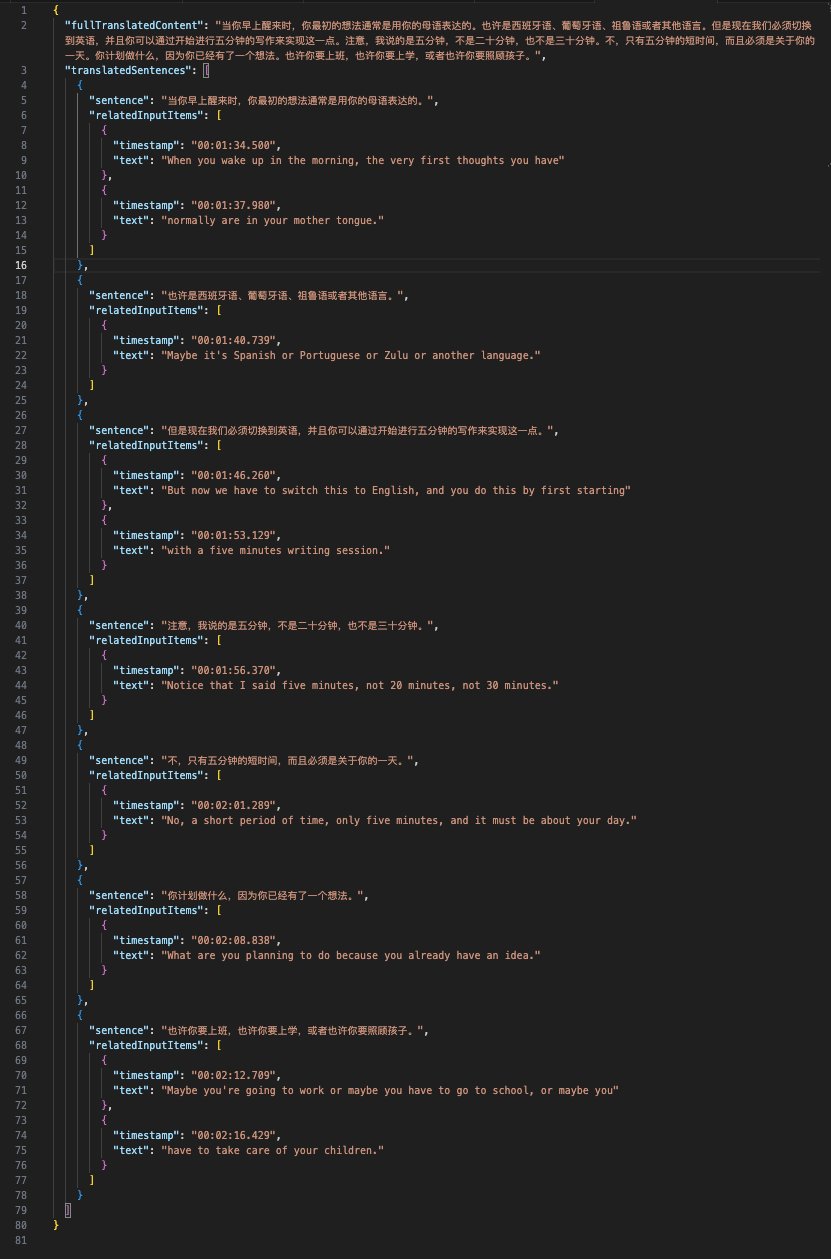
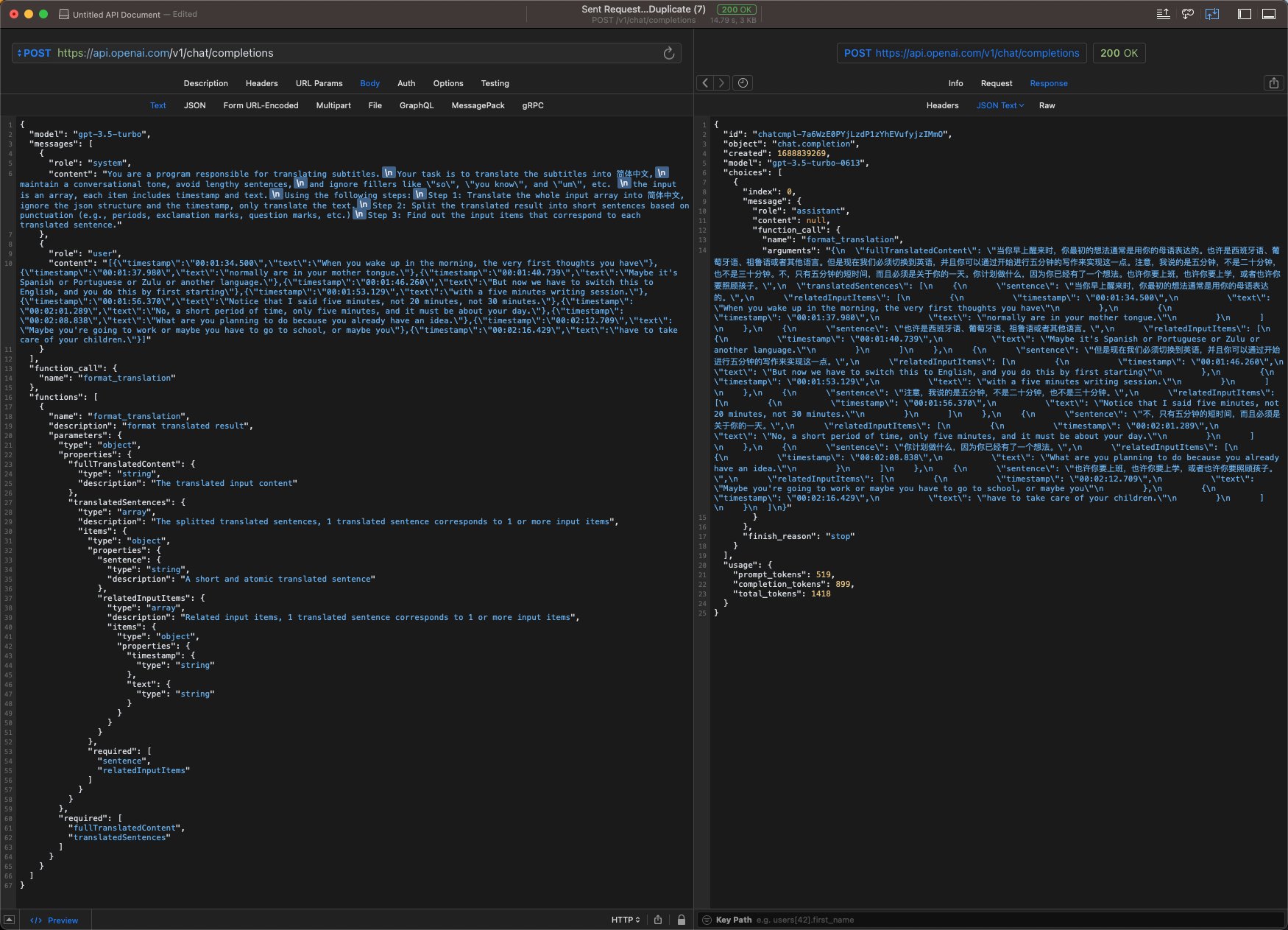
当然拿到的 JSON 结果后,还需要借助程序做一些解析和二次处理,没必要把所有事情都让 GPT 给你做,毕竟 GPT 生成的结果成本高,另外不够稳定。
最后总结一下:
在实际项目中,遇到类似需求,首先要考虑,哪些部分放到 LLM 帮你完成,并非所有事情都要让 LLM 做,毕竟它的成本比较高,并且输出结果并不是非常稳定。 当你明确了要让 LLM 帮你完成的任务,想清楚输入和输出是什么。 在遇到复杂的任务,借助 CoT 思路分解成一步步处理是必须的,同时要配套三板斧:
- CoT:将复杂任务分解成简单步骤
- 输出中间结果:对于关键步骤输出中间结果
- Function Calling:借助 FC 控制输出的格式