摘要
一句话总结 Google DeepMind 推出的 FunSearch 框架通过将数学问题转化为代码函数,结合大语言模型和自动评估器,实现了数学问题解决方案的自动生成与自我迭代优化。
关键点
- 核心成果:FunSearch 是 Google DeepMind 利用大语言模型(LLM)在数学领域取得的重大突破,实现了模型自主提出并验证数学问题解决方案。
- 命名由来:其前提条件是将数学问题描述为计算机代码中的“函数”(Function),这也是名称中“Fun”的来源。
- 系统架构:主要由三部分组成:大语言模型(基于现有代码生成创新解决方案)、评估器(防止错误或幻觉,评估并筛选最佳结果)和程序池(保存被评估器选出的最优代码)。
- 迭代机制:系统通过“从程序池选出程序 → LLM加工创新 → 评估器自动评估 → 最佳程序重回程序池”的循环,形成自我提升的闭环。
- 优化原理:借助代码和评估器,FunSearch 实现了类似 AlphaGo 的自动训练优化机制,持续驱动 LLM 解决问题。
- 相似案例:其工作思路与 Jim Fan 团队开发的 Voyager(GPT-4 自动玩 Minecraft)高度一致,均采用了“LLM生成代码 - 验证器执行校验 - 优秀代码存入库”的模式。
- 应用前景:这种“LLM - 代码 - 验证器”的框架被认为在未来具有广泛的创新应用潜力。
正文
FunSearch 是 Google DeepMind 最近利用大语言模型在数学领域的一个重大成果,甚至于你能从中看出前不久传闻中的 Q* 的影子,因为它本质上是实现了大语言模型自己提出解决数学问题的方案,并自己去验证解决方案。
它有一个前提条件,就是需要将数学问题描述成计算机代码“函数”,这就是 FunSearch 中“Fun”的由来,也就是“Function”。
下图很清楚的描述了 FunSearch 的工作原理。
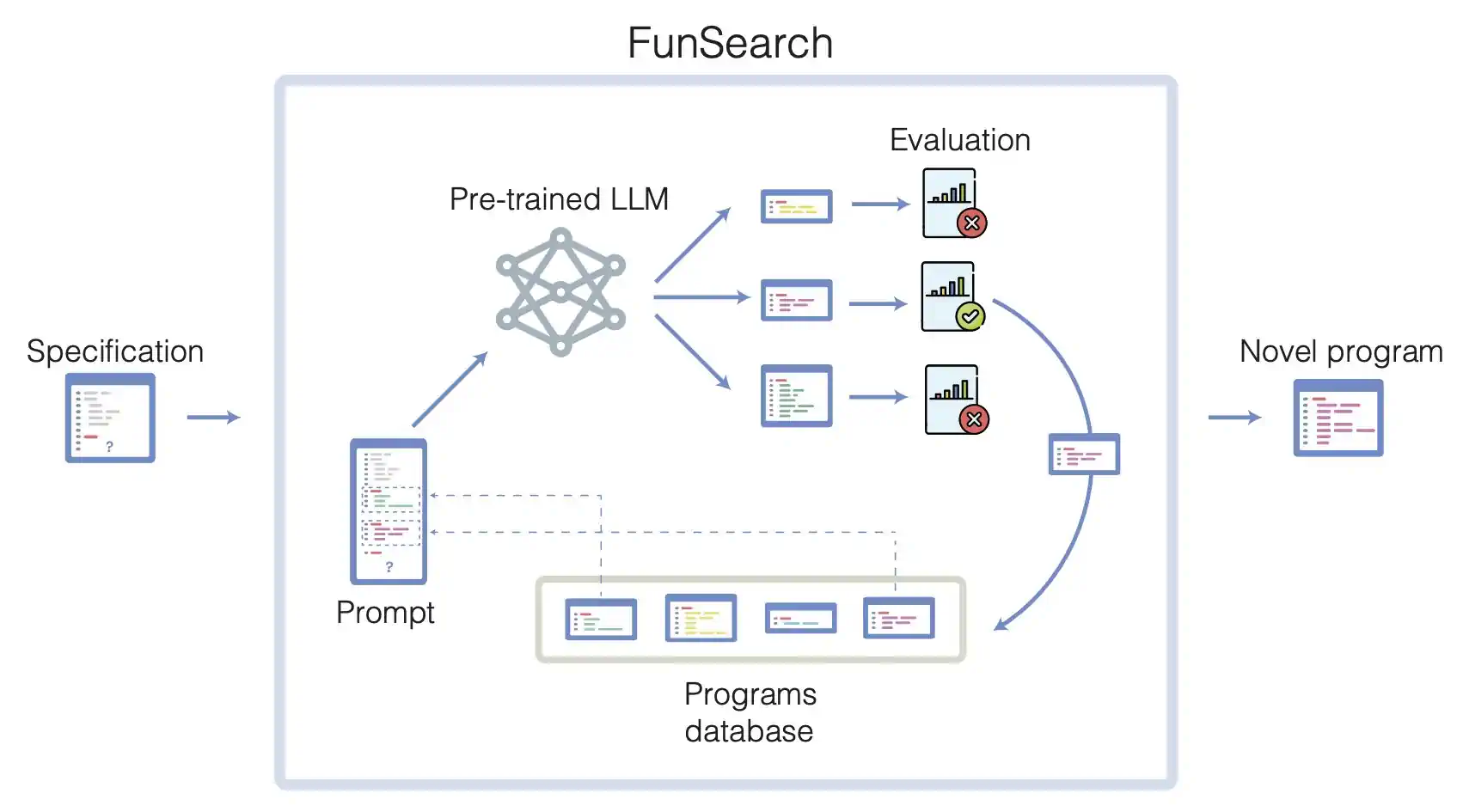
展示 FunSearch 过程的图解,包括代码截图、网络结构和带有勾选和叉号的图形。
FunSearch 主要由几个部分组成:
- 大语言模型:根据现有代码,提出创新性的解决方案,生成新的代码
- 评估器:防止错误或虚构的结果,评估生成的结果,选择最好的结果
- 程序池:保存已经生成好的并且评估器评选的最好的代码
FunSearch 是一个循环迭代的过程。在每一轮中:
- 系统会从现有程序池选取若干程序,交由 LLM 加工。
- LLM 在这些程序的基础上进行创新,生成新程序,并自动对它们进行评估。
- 表现最佳的程序将被重新加入程序池,形成一个自我提升的循环。
借助代码和评估器,FunSearch 就类似于 Alpha Go 的训练那样,实现了一套自动训练优化的机制,让 LLM 提出新的解决方案,持续不断地优化解决方案,最终解决问题。
另外如果你记得 Jim Fan 他们做过的 GPT-4 自动玩 Minecraft 的 Voyager https://twitter.com/DrJimFan/status/1662115266933972993,原理也是类似的:把 Minecraft 的操作转换成代码,GPT-4 生成技能代码,生成后去 Minecraft 中执行校验,优秀的技能代码最终保存到技能库。思路惊人的相似。
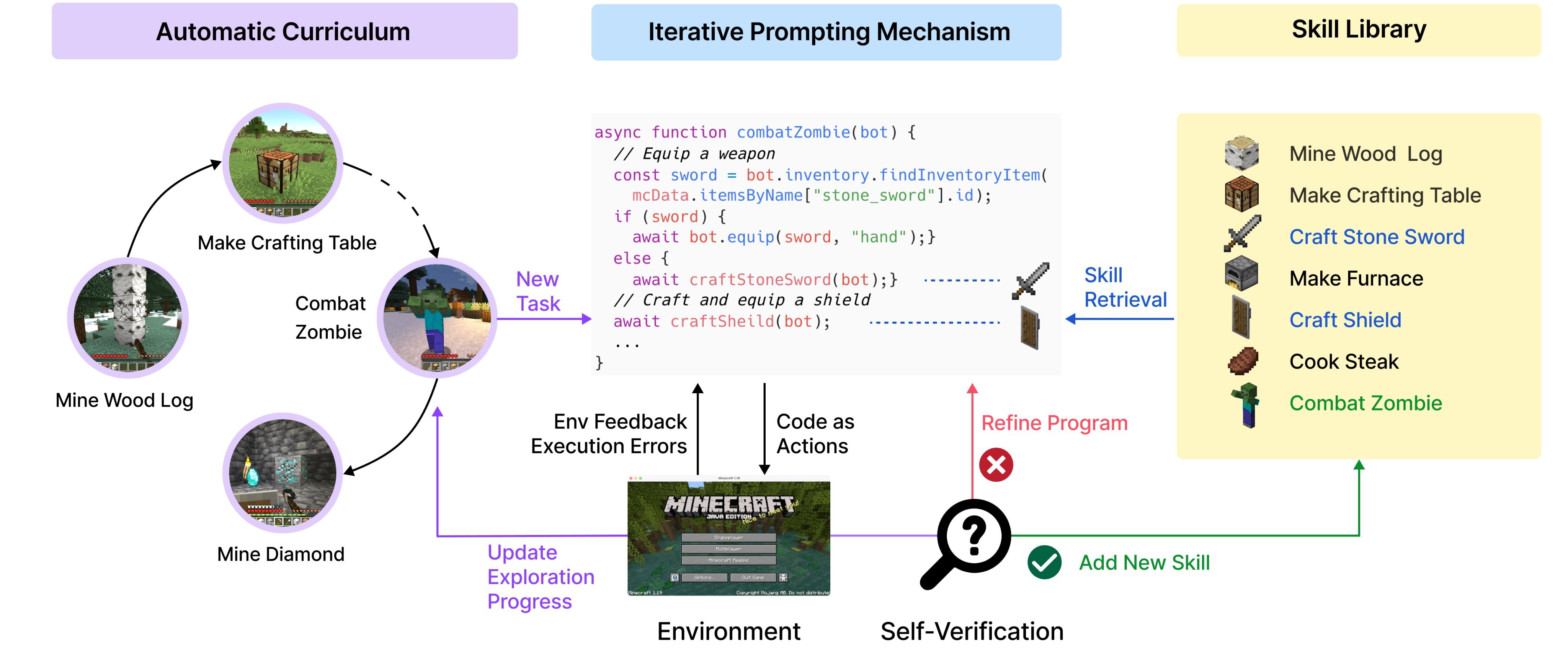
Voyager 完整的数据流设计,这个设计能在一个庞大的 3D 世界中推动终身学习的进行,而且不需要任何人工干预。
感觉这个(LLM - 代码 - 验证器)框架以后可以有越来越多的有创新的应用场景!
相关文章:《FunSearch:利用大语言模型在数学科学领域探索新奇发现 [译]》
相关文档
- 使用 Gemini Deep Think 加速数学与科学发现;关联理由:版本演进;说明:同属 Google DeepMind 的数学发现方向,体现了从 FunSearch 程序搜索到研究级推理与验证智能体的阶段性演进。
- 新论文:《WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models》;关联理由:观点一致;说明:两文都采用“模型生成方案 + 外部执行/验证 + 反馈迭代”的闭环机制来提升复杂任务求解能力。