摘要
Here is the summary of the provided content based on your requested format:
1) One-sentence summary
DeepSeek, in collaboration with Tsinghua and Peking University, introduced “DualPath,” an innovative inference architecture requiring only 5,000 lines of code modifications that resolves the KV-Cache I/O bottleneck in agentic LLMs and significantly boosts performance.
2) Key points
- Shift in Bottlenecks: In modern agentic LLM scenarios involving multi-turn interactions and long contexts, the primary system bottleneck has shifted from raw GPU computational power to I/O bandwidth limits during KV-Cache loading.
- Structural Flaw in Legacy Systems: Traditional Prefill-Decode (PD) separation architectures suffer from severe load imbalances, where the prefill engine’s network card is constantly maxed out while the decode engine’s card sits idle.
- The DualPath Solution: The new architecture introduces a secondary data route, allowing KV-Cache to be loaded from storage to the decode engine first, and then forwarded to the prefill engine via a high-performance RDMA network.
- High Impact, Low Code: Built on a self-developed inference framework, this system-level breakthrough was achieved with only about 5,000 lines of code modifications.
- Massive Performance Gains: In tests involving models up to 660B parameters, DualPath reduced job completion times by nearly half (a 1.87x performance boost), approaching the theoretical limit of “zero I/O overhead.”
- Scalability for Heavy Workloads: The performance advantages of DualPath become increasingly obvious as batch sizes and context lengths grow, demonstrating its effectiveness for highly I/O-intensive workloads.
- Foundation for DeepSeek V4: This architecture provides the crucial technical foundation for the upcoming DeepSeek V4 (and V4 Lite), which is expected to support a massive 1-million-token context window.
- A New Industry Paradigm: The research signals that future competition in AI infrastructure will rely just as heavily on data scheduling, bandwidth organization, and node coordination as it does on sheer hardware compute power.
3) Risks/gaps
- Network Interference Risk: Introducing a dual-path mechanism creates highly complex network traffic patterns that, if mismanaged, could interfere with latency-sensitive model execution communications and degrade overall performance.
- Dynamic Load Balancing Difficulty: Because real-world production workloads are highly dynamic and heterogeneous, it is incredibly challenging to calculate the optimal data path in real-time while keeping GPU and network resources perfectly balanced.
- Underlying Ecosystem Dependency: Despite the shift in focus from raw compute to data scheduling, the current DualPath implementation remains fundamentally based on CUDA and is tightly bound to the existing GPU ecosystem.
正文
继 DeepSeek V4 Lite 信息泄露后,DeepSeek 团队刚刚放出重磅技术成果 —— 联合清华大学、北京大学计算机科学学院,发布一篇顶会级重磅论文《DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference》,直击智能体时代 LLM 最致命的瓶颈 ——存储带宽墙。
论文地址:https://arxiv.org/pdf/2602.21548

本论文第一作者 Yongtong Wu(吴永彤)现为北京大学(PKU)博士生(根据学习经历推测是位 00 后),研究方向聚焦系统软件与大模型基础设施。在攻读博士期间,他在金鑫教授指导下开展系统软件相关研究,重点关注大语言模型推理基础设施的架构与性能优化问题。

此前,吴永彤于 2025 年获得北京大学信息学与计算机科学学士学位。本科阶段,他在北京大学计算机科学技术系助理教授黄群指导下,从事 RDMA 中间件开发工作,积累了高性能网络通信与分布式系统方面的工程经验。
2025 年 7 月,吴永彤加入 DeepSeek 系统组,参与下一代模型推理基础设施的建设工作。他的核心职责之一,是对大规模内部软件系统进行系统级优化,使其能够在不同硬件平台上实现高效、稳定的运行。这类工作本质上属于大模型基础设施(Infra)建设范畴,重点在于提升推理系统在复杂集群环境中的性能与资源利用效率。
智能体推理,正被 “带宽” 卡死
在最新发布的论文中,DeepSeek 将目光投向了一个正在迅速成形的新现实:大语言模型的核心形态,正在从“对话工具”升级为“智能体系统”。
过去,大模型主要处理单轮或少量轮次的问答——用户输入提示词,模型生成结果,交互结束。但如今,越来越多的应用不再是一次性问答,而是持续多轮、跨工具、跨环境的任务执行。例如代码助手、自主任务型 Agent,会在几十甚至上百轮交互中,不断调用浏览器、Python 解释器等工具,与外部环境交互,逐步完成目标。
在这种“人类—大模型—环境”的三方交互模式下,大模型处理的不再是孤立的提示,而是一个持续增长的长上下文。每一轮新增的内容可能只有几百个 token,但这些内容会不断累积,形成极长的历史上下文。
在传统推理场景中,性能瓶颈主要集中在计算能力上,例如 GPU 的算力和矩阵运算效率。但在智能体负载下,情况发生了变化。
由于是多轮对话、短内容追加的模式,大部分历史上下文都可以被复用。技术上,这体现在 KV-Cache(用于存储模型历史注意力计算结果的缓存)命中率通常可以达到 95% 以上。也就是说,大部分计算不需要重新做,只需要把已有的 KV-Cache 重新加载进来继续使用。
问题在于——加载这些缓存本身,变成了瓶颈。
换句话说,在智能体工作负载下,系统越来越呈现出“高 I/O 密集型”的特征。真正决定吞吐量的,不再是模型算得有多快,而是 KV-Cache 能不能被高效加载。
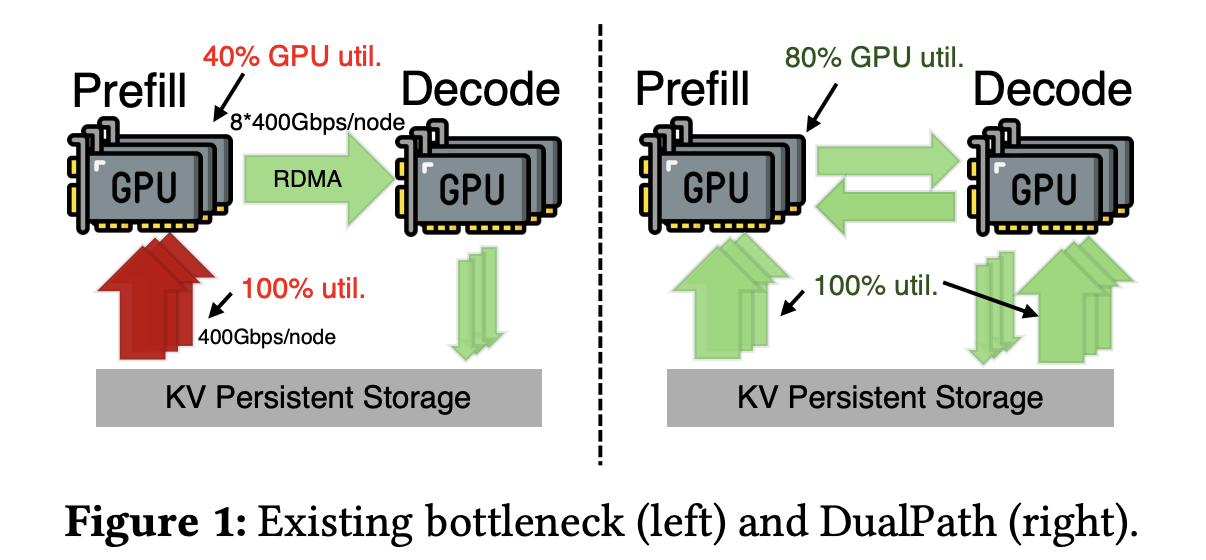
但主流的 PD 分离(Prefill-Decode Disaggregation)推理架构,存在天生缺陷:
-
Prefill 引擎网卡被占满长上下文带来海量 KV-Cache,预填充节点的存储网卡长期跑满,成为 I/O 瓶颈。
-
Decode 引擎网卡大量闲置解码侧只负责逐词生成,存储带宽利用率极低,资源严重浪费。
-
负载失衡 + 网络拥塞单路径加载 KV-Cache,延迟敏感的生成流量与大数据传输互相干扰,集群效率上不去。
一句话:GPU 算力再强,也在等数据;网卡一边堵死、一边空闲。这就是 PD 分离架构绕不开的性能天花板。
这种结构性失衡,使得系统整体吞吐量被预填充引擎“卡死”。理论上可以为预填充引擎扩容带宽,但在通用集群环境中,这种扩容成本高昂且难以落地。
因此,DeepSeek 认为,真正可行的优化方向不是单点扩容,而是重新设计 KV-Cache 的加载方式,让所有引擎的 I/O 带宽都被利用起来。
此前已有研究尝试缓解 KV-Cache 加载瓶颈。
例如,有方案将 KV-Cache 缓存在大规模分布式 DRAM 池中,并通过亲和性调度提升命中率。但这种方式对内存资源依赖极高,在强化学习推演等内存紧张场景下难以使用;而在在线服务这种工作集巨大的场景中,使用 DRAM 替代 SSD 成本过高。
也有研究尝试通过压缩或减少检索数据量来降低加载开销,但这些方法都没有解决一个核心问题:不同引擎之间存储 I/O 负载的不均衡。
DualPath:双路径加载 KV-Cache 及技术挑战
DualPath 通过创新双路径 KV-Cache 加载机制,从架构层面突破传统推理瓶颈。
其核心思想很直接:KV-Cache 的加载不应当只围绕预填充引擎。
在传统架构中,KV-Cache 只能从存储直接加载到预填充引擎。而 DualPath 增加了一条新的路径——KV-Cache 可以先加载到解码引擎,再通过高性能 RDMA 网络转发到预填充引擎。
于是,系统中出现了两条加载路径:
-
存储 → 预填充引擎 PE(传统路径)
-
存储 → 解码引擎 DE → 预填充引擎 PE(新增路径)
系统可以根据实时负载动态选择路径,从而把一部分 I/O 压力转移到解码引擎,重新分配网络带宽,缓解预填充侧的带宽瓶颈。
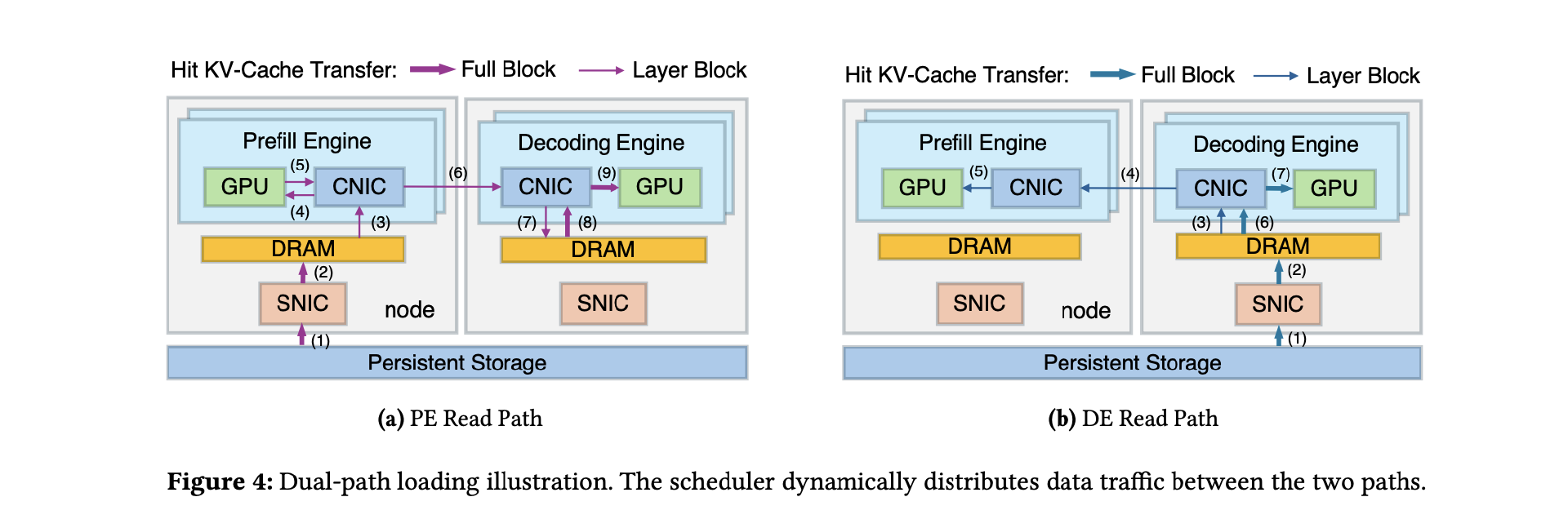
本质上,这是一次对“数据路径”的重构,而非单纯的硬件堆叠。
搭配全局动态调度器,DualPath 可实时均衡预填充引擎与解码引擎的负载,彻底解决 PD 分离架构下 KV-Cache 读取负载失衡问题,为智能体长上下文、多轮交互推理提供底层算力支撑,也为即将到来的 DeepSeek V4 系列奠定关键技术底座。
不过,引入双路径并不简单。DeepSeek 在论文中指出了两个关键挑战:
第一,新增路径会引入更复杂的网络流量模式。如果管理不当,可能干扰模型执行中对延迟敏感的通信操作,反而拉低整体性能。
第二,在真实生产环境中,工作负载是动态且异构的。系统必须实时决定采用哪条加载路径,同时保证 GPU 和网卡资源都处于均衡状态。
为此,DualPath 引入了三项关键设计:
-
优化的数据路径设计,确保在常见的预填充/解码比例下不会产生天然拥塞;
-
以计算网卡为核心的流量管理机制,将 KV-Cache 传输流量与对延迟敏感的模型推理通信隔离;
-
动态调度策略,实现预填充与解码引擎之间计算与网络资源的联合负载均衡。
系统实现
DualPath 基于自研推理框架实现,CUDA 内核整合了 FlashMLA、DeepGEMM 和 DeepEP,与当前主流的开源框架对齐;DualPath 在该框架上的修改量约为 5000 行代码。系统采用 3FS 作为分布式存储,并使用类 io_uring 的接口实现内核旁路,提升存储访问效率。
为了验证架构本身的效果,实验环境采用了高规格 GPU 集群:
-
每台服务器:8 张英伟达 Hopper GPU + 双 CPU;
-
每节点:8 张 400 Gbps RDMA 网卡(计算网络);
-
另配 1 张连接 3FS 的存储网卡;
-
计算网络与存储网络物理隔离;
-
集群级 3FS 不设 DRAM 缓存,可跑满 400Gbps 存储带宽。
这种配置的目的很明确:排除网络瓶颈和缓存干扰,把性能差异集中到 KV-Cache 加载路径本身。
实验选取三类模型,覆盖不同规模和架构:
-
DeepSeek V3.2 660B(MoE 架构)
-
其 27B 降尺度版本(内部实验模型)
-
Qwen Qwen2.5-32B(GQA 稠密模型)
前两者代表大规模稀疏 MoE 模型,后者为典型稠密模型。测试目标是验证 DualPath 是否对不同架构都有效。
离线场景模拟强化学习训练中的推演阶段:多个智能体同时运行,统计全部任务完成所需时间(JCT)。结论很直接:
-
批次越大、上下文越长,DualPath 优势越明显;
-
在部分大规模配置下,基于 SGLang + Mooncake 的系统甚至无法稳定完成任务;
-
在 660B 模型上,DualPath 相比原始框架最高将作业完成时间缩短至 1/1.87,接近“零 I/O 开销”的理论上限(Oracle);
-
27B 与 Qwen 32B 也呈现类似趋势。
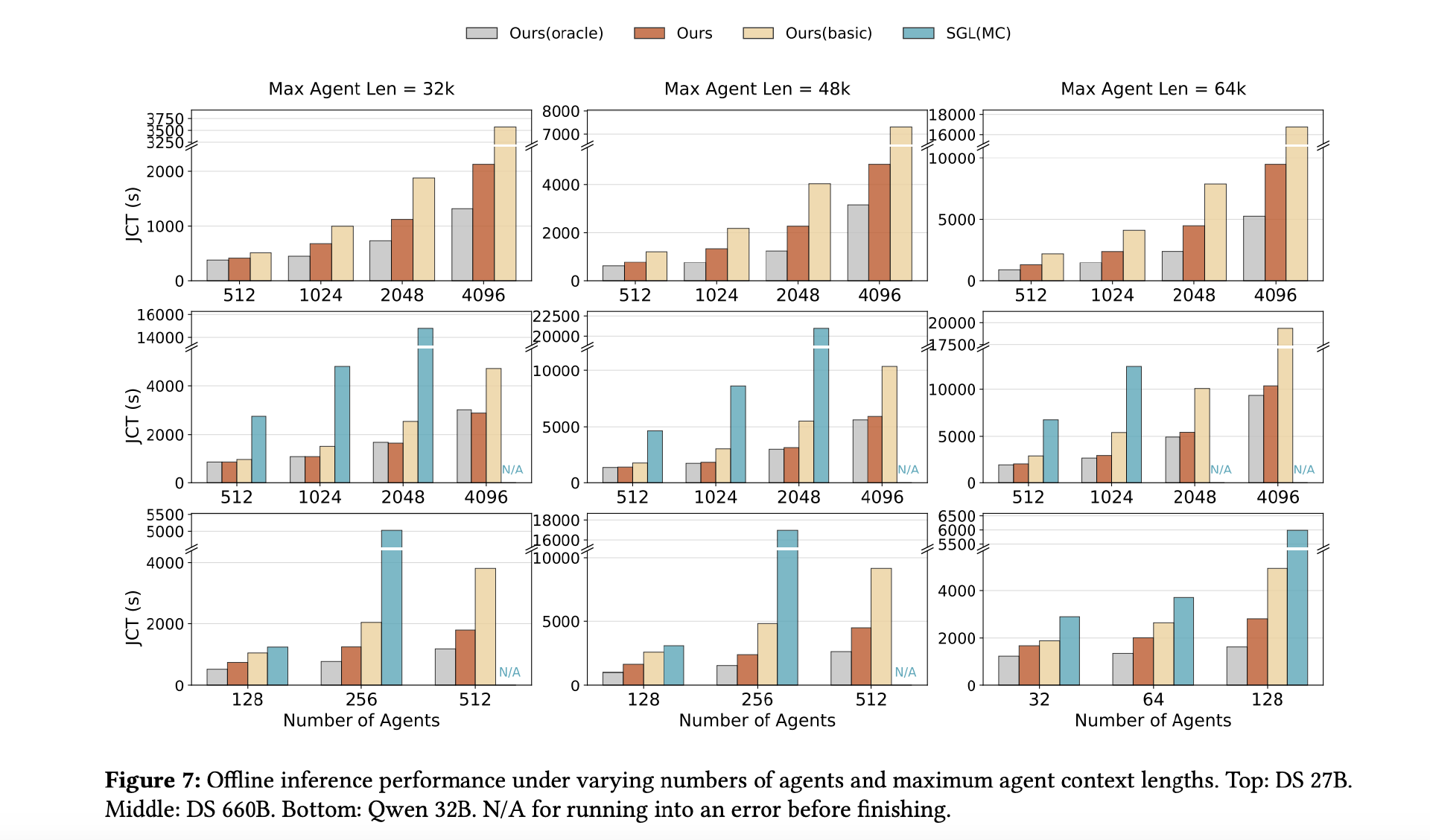
这说明,在长上下文智能体场景中,瓶颈确实集中在 KV-Cache 的 I/O。
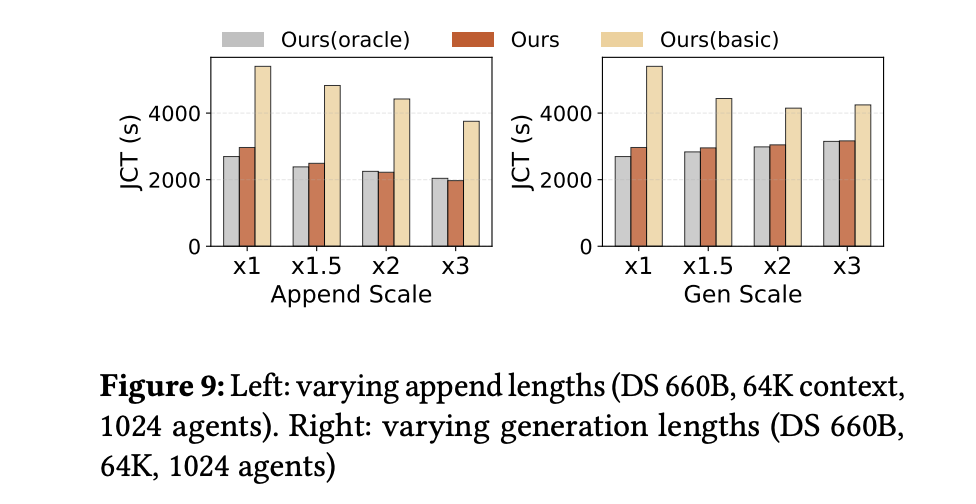
此外,实验还刻意放大每轮的追加 token 或生成 token 长度。结果显示:
-
当追加长度增加(即 GPU 计算变重),原始框架性能逐渐逼近 DualPath;
-
当生成长度增加(预填充频率下降),I/O 压力减轻,性能差距缩小。
这说明:当 GPU 计算成为瓶颈时,DualPath 不会额外拖慢系统;而当 I/O 成为瓶颈时,DualPath 优势显著。
在不同追加比例下,DualPath 对原系统的加速比在 1.82–1.99 倍之间。
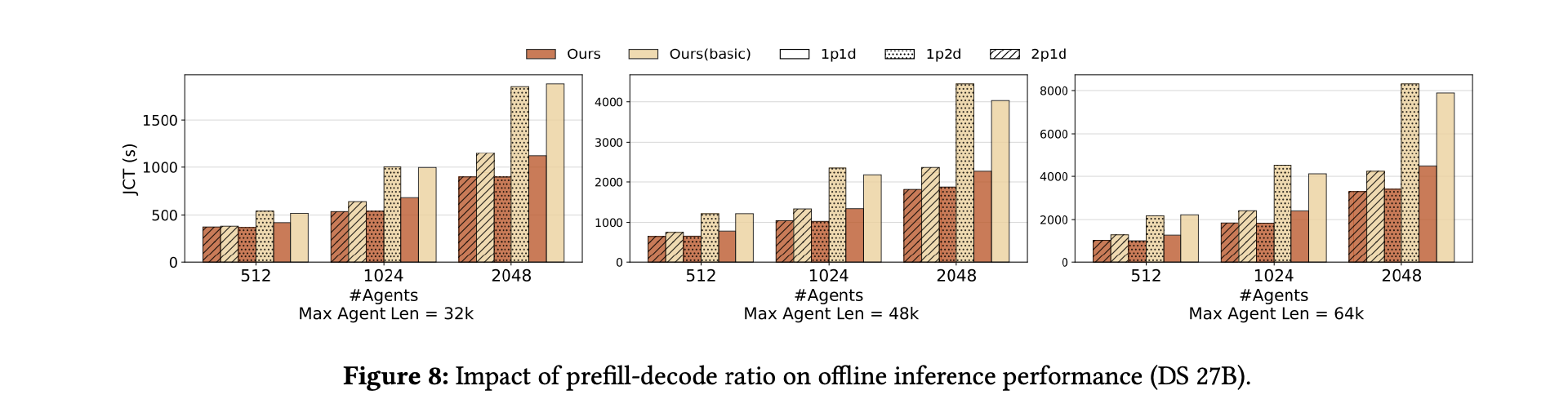
论文测试了 1P1D、2P1D、1P2D 等多种配置(P=预填充节点,D=解码节点)。关键观察:
-
原始系统只能利用预填充节点的存储带宽;
-
DualPath 可以利用所有节点的存储带宽;
-
在所有比例下,DualPath 都显著优于原系统;
-
平均加速比达 1.64 倍,最高 2.46 倍。
这从系统层面验证了论文的核心论点:在智能体负载下,存储带宽才是主导瓶颈,而不是算力。
从实验结果可以抽象出一个更宏观的判断:在长上下文智能体负载下,模型算力已经不是决定性因素。真正限制吞吐的,是 KV-Cache 的加载路径,以及存储带宽在不同引擎间的分配方式。
DualPath 并没有减少 KV-Cache 数据量,也没有压缩数据,而是通过重构加载路径,让所有节点参与 I/O 分担。本质上,这是一次系统资源再分配,而不是算力扩张。
性能瓶颈正从“算得快”转向“数据调度得好”
在外界仍在讨论模型能力与参数规模时,围绕 DeepSeek 的两条线索正在交汇:一边是被曝提前向华为等国内芯片厂商开放新一代模型适配权限;另一边,是其最新论文提出的推理系统架构 DualPath——一套针对智能体长上下文场景重构 KV-Cache 加载路径的系统设计。
如果两者放在一起看,问题就不再只是“模型升级”,而是一次从硬件协同到系统架构层面的整体调整。
据知情人士透露,DeepSeek 已为包括华为技术在内的国内供应商预留数周时间,对即将推出的 DeepSeek V4 进行软件适配与性能优化。这一做法打破了行业惯例。通常,大型模型在正式发布前会向英伟达、AMD 等头部芯片厂商提供预览版本,以便在 CUDA、驱动和通信栈层面完成针对性优化,从而确保模型在主流 GPU 上获得最佳性能。
此前 DeepSeek 也曾与英伟达技术团队保持合作。因此,如果上述消息属实,这意味着其硬件协同策略正在发生变化。
但目前相关说法尚未得到官方确认。
与此同时,另一条消息显示,DeepSeek V4 Lite(代号“sealion-lite”)正在密集测试阶段。已披露的信息包括:支持 100 万 tokens 的上下文窗口,采用原生多模态架构,并在效果上显著优于当前网页端与 App 端模型。至少已有一家推理服务商获得访问权限,但签署了严格的保密协议。百万级上下文长度本身就是一个关键信号——它意味着 KV-Cache 规模将大幅膨胀,模型运行将高度依赖缓存复用与高带宽数据调度能力。
这恰好与 DeepSeek 在论文中提出的 DualPath 架构形成呼应。DualPath 的核心思路是增加一条“存储—解码—预填充”的加载路径,使 KV-Cache 可以先加载到解码节点,再通过 RDMA 网络转发至预填充节点,从而将存储带宽压力在多个节点间重新分配。
如果将这一系统级优化与 V4 Lite 的百万上下文能力结合来看,其技术逻辑是连贯的。更长的上下文意味着更大的 KV-Cache;更大的 KV-Cache 意味着更重的 I/O 压力;而更重的 I/O 压力,恰恰需要通过类似 DualPath 的带宽重构机制来化解。在这种架构下,系统性能的决定因素更多取决于整体带宽调度能力与节点协同效率,而不是单卡算力的绝对领先。
但值得注意的是 DualPath 仍然基于 CUDA 实现,底层依然围绕 GPU 生态展开。当性能瓶颈从“算得多快”转向“数据调度得多好”时,不同硬件之间的竞争维度就会发生变化。算力差距仍然重要,但带宽组织能力、网络架构设计以及系统调度策略,开始成为同等关键的变量。
参考链接: