摘要
1) 一句话摘要 借助 GPT-5.1 的低延迟与高可控性,Tolan 构建了一款通过逐轮重建上下文和高效向量记忆检索来维持稳定人设与自然长对话的语音交互 AI 伴侣。
2) 核心要点
- 显著降低延迟: 接入 OpenAI GPT-5.1 与 Responses API 后,Tolan 的语音启动时间缩短了超过 0.7 秒,大幅提升了对话的自然流畅度。
- 逐轮重建上下文: 摒弃传统的提示词缓存机制,在每一轮对话中从头重建上下文窗口(融合近期摘要、人格卡片、检索记忆、语气指导等),以实时适应突发的话题转换。
- 毫秒级记忆检索: 采用
text-embedding-3-large模型进行向量嵌入,并存储在 Turbopuffer 向量数据库中,将查询延迟严格控制在 50 毫秒以内。 - 自动化记忆维护: 系统在夜间运行记忆压缩任务,自动清理低价值或冗余条目,并整理消除矛盾信息,以维持高质量的记忆库。
- 精准的角色控制: 结合内部科幻作家设计的“人格骨架”与并行的情绪监控系统,GPT-5.1 能够忠实执行分层提示指令,显著减少长对话中的角色漂移。
- 业务指标提升: 上线基于 GPT-5.1 的系统后,Tolan 的记忆召回失误率下降了 30%,用户次日留存率提升了 20% 以上。
- 市场表现: 自 2025 年 2 月推出以来,月活跃用户(MAU)已超 20 万,获得 4.8 星评级及超 10 万条 App Store 评论。
- 未来演进方向: 计划推进更紧凑的记忆压缩与更智能的检索逻辑,并致力于构建整合语音、视觉与上下文的真正多模态语音智能体。
正文
借助 GPT‑5.1,Tolan 打造了一款语音应用,专门针对低延迟、精准上下文与稳定角色人格进行优化,确保对话在不断推进中始终保持自然连贯的体验。

Tolan(在新窗口中打开) 是一款语音交互 AI 伴侣。用户可与一位个性化的动画角色交谈,该角色能随时间的推移从对话中持续学习。
其开发团队 Portola 经验丰富,此前已有成功的创业退出案例。这款应用的设计初衷是支持持续、开放式的长对话,而不是几轮简单的快问快答。“我们见证了 ChatGPT 的崛起,也认定语音将是下一个前沿,”Portola 联合创始人兼首席执行官 Quinten Farmer 说道,“但语音更难。这不仅仅是回复文本提示,而是在进行一场实时、即兴的对话。”
语音 AI 对延迟和上下文管理的要求更高,但相比文本,它也能开启更开放、更具探索性的互动。
随着基础模型变得更快、更便宜、能力更强,团队将聚焦于两个关键杠杆:记忆系统与角色设计。Portola 构建了一个角色驱动的世界,由获奖动画师和科幻作家共同塑造,并利用实时上下文管理系统,在对话展开过程中保持角色人格与记忆的一致性。
GPT‑5.1 模型的发布是一个转折点。它在可控性和延迟方面带来的巨大提升,将这些关键部分有机结合,从而解锁了响应更迅捷、互动性更强的语音体验。
“GPT-5.1 为我们提供了所需的可控性,让我们能够将把心目中的角色真正呈现出来。它不仅是更聪明,更关键是能忠实体现我们想要打造的语气和个性。”
Portola 首席执行官 Quinten Farmer
为自然的语音交互而设计
Tolan 的架构完全围绕语音需求而构建。语音用户期望即时、自然的回应,即使对话中途发生转变。Tolan 必须快速响应、追踪变化的话题,并确保在毫无延迟或语气漂移的情况下保持一致的个性。
为达到自然感,对话需要近乎即时的低延迟。在接入 OpenAI GPT‑5.1 与 Responses API 之后,语音启动时间缩短了超过 0.7 秒,这大幅提升了对话的流畅体验。
同样关键的是系统如何处理上下文。与许多在多轮对话中缓存提示的智能体不同,Tolan 在每一轮对话中都从头开始重建其上下文窗口。每次上下文重建都会纳入近期消息摘要、人格卡片、向量检索的记忆、语气指导和实时应用信号。这种架构让 Tolan 能够实时适应突兀的话题转换,这是实现自然语音交互的基本要求。
“我们很快意识到,仅靠缓存提示根本行不通,”Quinten 说道,“用户总是在不断换话题。要做到体验流畅,系统就必须能在对话过程中即时调整。”
这种实时重建的方法在技术上要求很高,但却是 Tolan 成功的基石。
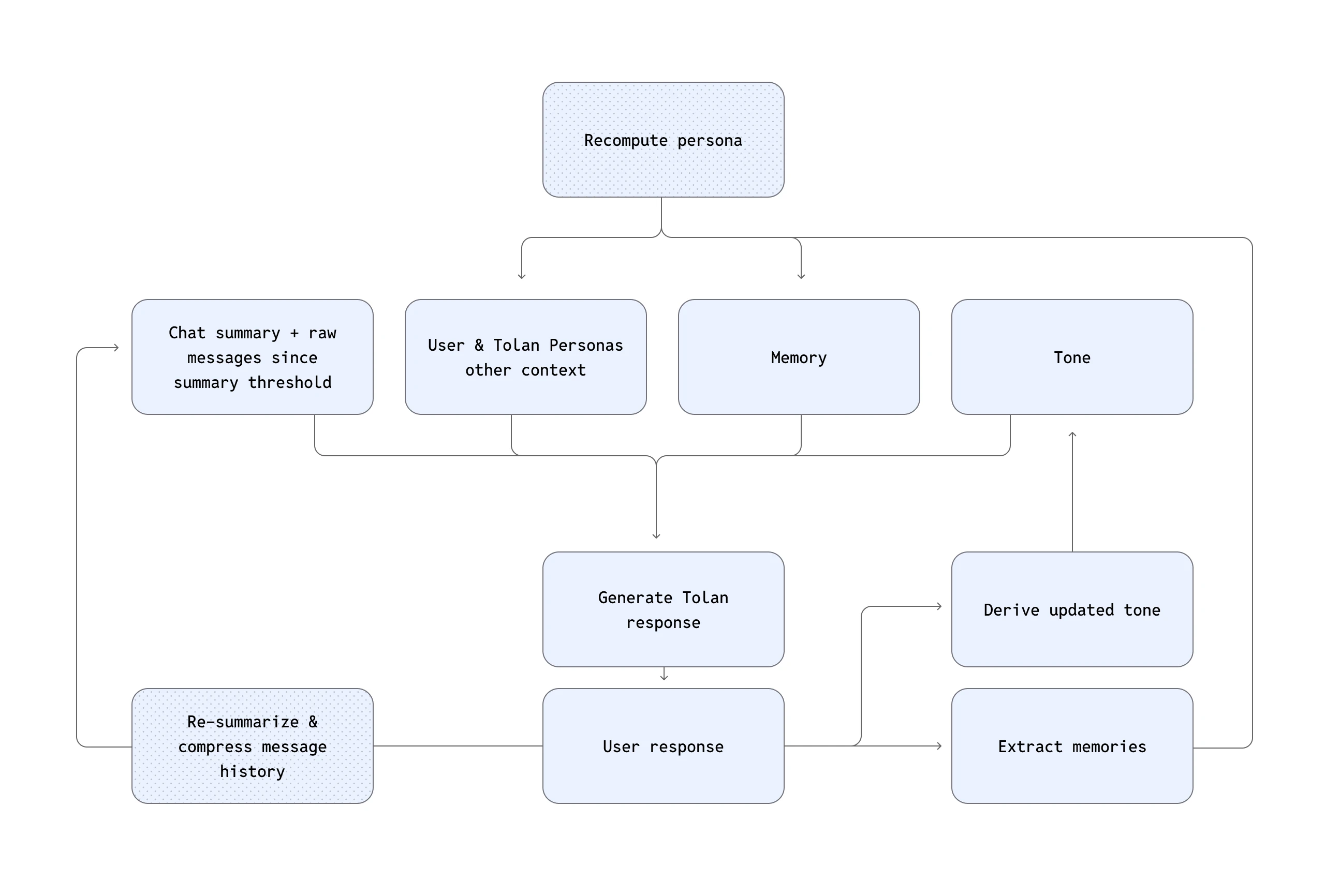
构建持久连贯的记忆与个性
上下文处理固然重要,但尚不足以让对话随时间推移仍保持连贯感。为了支持冗长、非线性的对话,Tolan 构建了一个记忆系统,该系统不仅保留事实和偏好,还捕捉情感层面的“氛围”信号—这些线索会引导 Tolan 以更合适的方式作出回应。
这些记忆通过 OpenAI 的 text-embedding-3-large 模型进行向量嵌入,并存储在 Turbopuffer(一个高速向量数据库)中,可将查询延迟控制在 50 毫秒以内。这种速度对于实时语音交互至关重要。在每一轮对话中,Tolan 都会结合用户的最新消息和系统生成的问题(例如“用户的配偶是谁?”)来触发记忆召回。为了保持记忆质量,Tolan 还会在夜间运行压缩任务,删除低价值或冗余条目(如“用户今天喝了咖啡”),并整理、消除其中的矛盾信息。
角色人格的管理也同样严格。每个 Tolan 角色都基于独特的“人格骨架”进行初始化,该骨架由团队内部的科幻作家创作,并由行为研究员进行优化。这让 Tolan 既有稳定的人设,又能保持灵活,能够随着时间推移不断适应用户,与用户一同演进。
一个并行系统会监控对话的情绪基调,并动态调整 Tolan 的回应方式。这使 Tolan 能够根据用户提示,在俏皮与沉稳之间无缝切换,同时保持其核心人格。
向 GPT‑5.1 的迁移是一个关键转折点。自此以后,从语气框架、记忆注入到人格特质,分层的提示指令都能被模型更加忠实地执行。过去需要靠小技巧才能奏效的提示,如今都能照原本设想的方式运行。
“我们的内部专家第一次感觉到,模型真的在‘倾听’,”Quinten 说道,“在长对话中,指令依然保持清晰有效,角色人格特质也保持稳定,整体漂移明显减少。”
这些改变累积成一种更一致、更可信的人格,进而打造出更具吸引力的用户体验。Tolan 团队也看到了清晰、可量化的成效:在基于 GPT‑5.1 的角色系统上线后,记忆召回失误率下降了 30%(基于产品内的挫败信号),用户次日留存率则提升了 20% 以上。
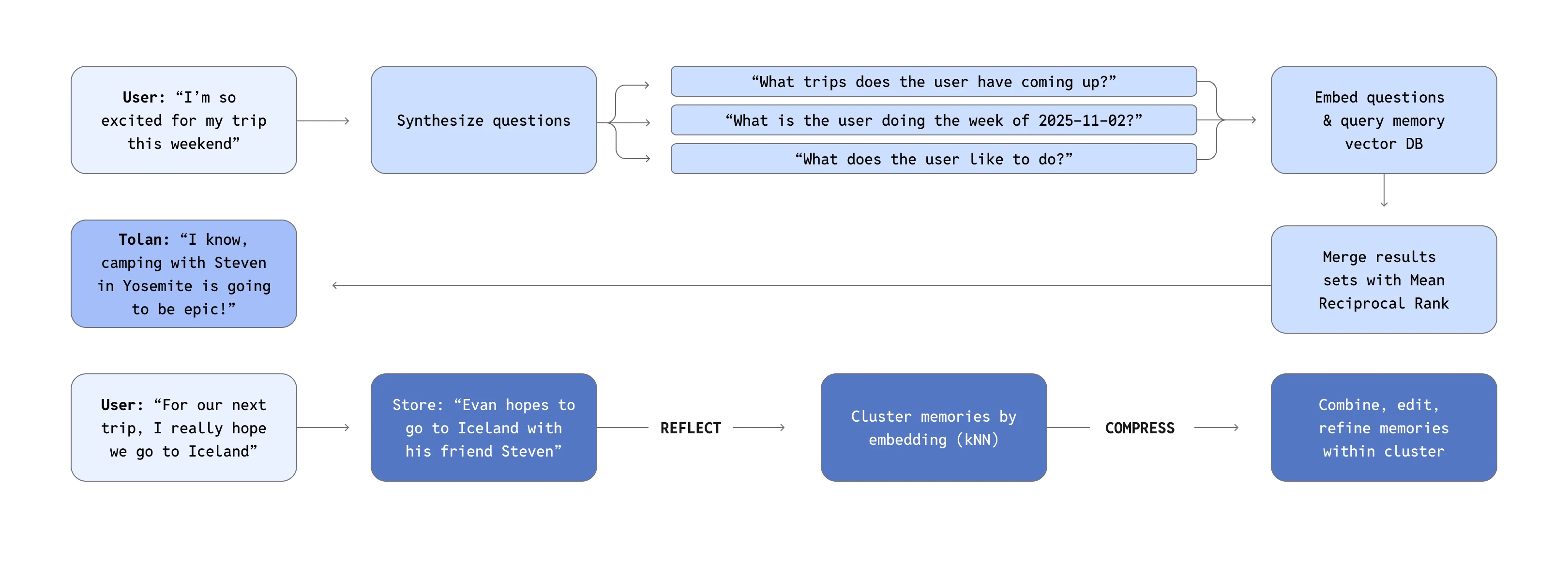
Tolan 构建自然语音智能体的核心原则
随着 Tolan 的不断演进,团队也逐渐沉淀出一套核心原则,用来指导语音架构的设计与升级:
- **为对话的多变性而设计:**语音对话随时可能在一句话中途就切换话题。系统需要同样快速地转向才能感觉自然。
- **将延迟视为产品体验的一部分:**亚秒级响应速度决定了语音智能体是更像在对话,还是更像机械应答。
- **将记忆设计成检索系统,而非对话记录:**与庞大的上下文窗口相比,高质量压缩和快速向量搜索更能保证角色表现的一致性。
- **每轮对话都重建上下文:**不要试图用更大的提示来对抗漂移。每轮都重新生成上下文,能让智能体在对话不断拐弯时依然保持回应扎实、有据可依。
这些经验共同构成了 Tolan 下一阶段创新的基础,并为语音 AI 的发展方向指明了道路。
拓展语音 AI 的可能性
自 2025 年 2 月推出以来,Tolan 的月活跃用户已增长至 20 万以上。其 4.8 星评级和超过 10 万条 App Store 评论,凸显了该系统在漫长、多变对话中保持一致性的卓越能力。一位评论者指出:“他们记得我们两天前聊过的事情,并能把这些带回我们今天正在进行的对话中。”
这些用户反馈直接映射到底层架构:低延迟的模型调用、逐轮上下文重建、以及模块化的记忆和人格系统。在这些因素的共同作用下,Tolan 能够跟踪话题变化、保持语气,并在不依赖庞大而脆弱的提示的情况下,让回复有据可依。
展望未来,Tolan 计划进一步加大在可控性和记忆优化上的投入,重点推进更紧凑的压缩方式、更智能的检索逻辑和更精细的角色调优。长期目标是拓展语音界面的能力:不仅要能够响应,还要具备上下文感知能力,并能在对话过程中持续做出动态调整。
Quinten 说道,“下一个前沿是构建不仅响应迅速,而且真正多模态的语音智能体,能够将语音、视觉和上下文整合到一个统一且高度可控的系统中。”
相关文档
- 走进 OpenAI 的自研数据智能体;关联理由:延伸思考;说明:两文都将“分层上下文 + 向量检索记忆”作为 Agent 稳定性的关键机制,但分别落在语音交互与企业数据分析场景。