摘要
1) 一句话总结 2026年清华 AGI-Next 峰会上,来自腾讯、阿里、智谱及学术界的专家探讨了 AI 在 To B 与 To C 领域的发展分化、下一代技术范式、Agent 演进路线,以及中国 AI 企业在全球竞争中的核心差距与突围机会。
2) 关键要点
- 应用场景分化:To C 与 To B 出现明显分化。To C 用户对极限智能感知不强(多作为增强版搜索引擎),而 To B 场景对高智能模型有强烈的溢价支付意愿,以换取更高的生产力和准确率。
- 企业战略分化:国内头部 AI 企业不再盲从 OpenAI,开始走向差异化:腾讯强调场景感知(Context),阿里主攻开源生态,智谱押注代码生成(Coding)。
- 下一代范式驱动力:单纯扩大规模(Scaling)的性价比正在降低,智谱唐杰提出“智能效率(Intelligence Efficiency)”将成为核心竞争力,即用更少投入获得更大智能增量。
- 学术界机遇:高校与工业界的算力差距已从两年前的万倍缩小至约10倍,学术界在孵化新范式方面迎来新机会。
- Agent 四阶段演进:杨强提出基于“目标定义”和“规划定义”的四个阶段,最终局(第四阶段)将是大模型内生地自主定义目标与规划路径。
- Agent 的核心价值:通用 Agent 的最大魅力和核心能力在于解决用户寻遍各处都找不到答案的“长尾问题”。
- 应用层创业逻辑:纯“套壳”创业护城河极浅,高价值的应用层功能极易被模型公司直接整合进基座;创业者必须建立独特的数据、用户或工作流壁垒。
3) 风险与差距(基于原文明确提及)
- 算力与研发资源差距:美国 AI 公司的算力规模比中国大 1-2 个数量级。美国将大量算力投入下一代研究(Research),而中国公司的算力绝大部分被用于产品交付,缺乏探索资金。
- 创新基因与风险偏好差距:中国在工程复现和商业化上具有优势,但过于追求“确定性”,缺乏愿意承担极高风险去探索未知新范式(如持续学习)的人才和环境。
- Scaling 投资回报风险:模型规模扩张带来的计算成本极其高昂(投入10亿、20亿),但带来的智能收益递减,回报可能微薄。
- 模型理论缺陷风险:受哥德尔不完备定理限制,大模型无法自证清白,必定存在无法完全消灭的幻觉问题。
正文
1 月 10 日,清华 AGI-Next 峰会的圆桌对话:中国 AI 的下一步,主持人:李广密,嘉宾:阿里千问的林俊旸、智谱的唐杰、联邦学习先驱杨强、刚从 OpenAI 回国加入腾讯的姚顺雨,整容强大。
我最感兴趣的还是姚顺雨的发言,毕竟他刚从 OpenAI 跳槽到腾讯不到一个月,这是他首次公开亮相,不过是通过视频远程参加。
主持人李广密在两个小时里问了很多好问题,我只是挑几段有价值的对话分享一下。
谁在分化?
李广密先问了个分化的问题:
“硅谷几家公司开始走不同的路,Anthropic 专注企业和 Coding,OpenAI 做 To C,中国呢?”
姚顺雨说有两个大的分化正在发生:
“第一个感受是 To C 和 To B 发生了明显的分化。非常有意思的一点是我们今天用 ChatGPT 和去年相比的话,感受差别不是太大。但是相反,Coding 夸张一点来讲,已经在重塑整个计算机行业做事的方式,人已经不再写代码,而是用英语和电脑去交流。”
他的解释很直接:大部分人大部分时候不需要那么强的智能。今天 ChatGPT 写抽象代数的能力变强了,但普通用户感受不到。在中国,很多人把它当搜索引擎的加强版用。
但 To B 完全不一样。“智能越高,代表生产力越高,值钱的也越来越多。”他举了个例子:一个模型 200 美元/月,差一点的 50 美元或 20 美元,很多美国人愿意花溢价用最好的。为什么?因为一个年薪 20 万美元的人,每天做 10 个任务,强模型做对八九个,弱模型做对五六个。问题是你不知道哪五六个是对的,需要花额外精力去监控。
第二个分化是垂直整合和分层的区别。To C 产品倾向于模型和产品紧密耦合,像 ChatGPT 或豆包。但 To B 正好相反,模型越强,应用层的机会反而越大。
林俊旸接了一句:
“公司也不一定有那么多基因之分,一代一代的人可能就塑造了这些公司。比如说今天顺雨到腾讯之后,可能腾讯变成一个有着顺雨基因的公司。”
唐杰则认为:
“从 DeepSeek 出来之后,搜索这一仗已经结束了。我们应该想的是下一仗是什么。”
他透露智谱内部“争论了很多个晚上”,最后赌在了 Coding 上。
看起来三家已经开始分化:腾讯强调 Context(场景感知),阿里做开源生态,智谱押注 Coding。都不是盲目跟随 OpenAI 的路。
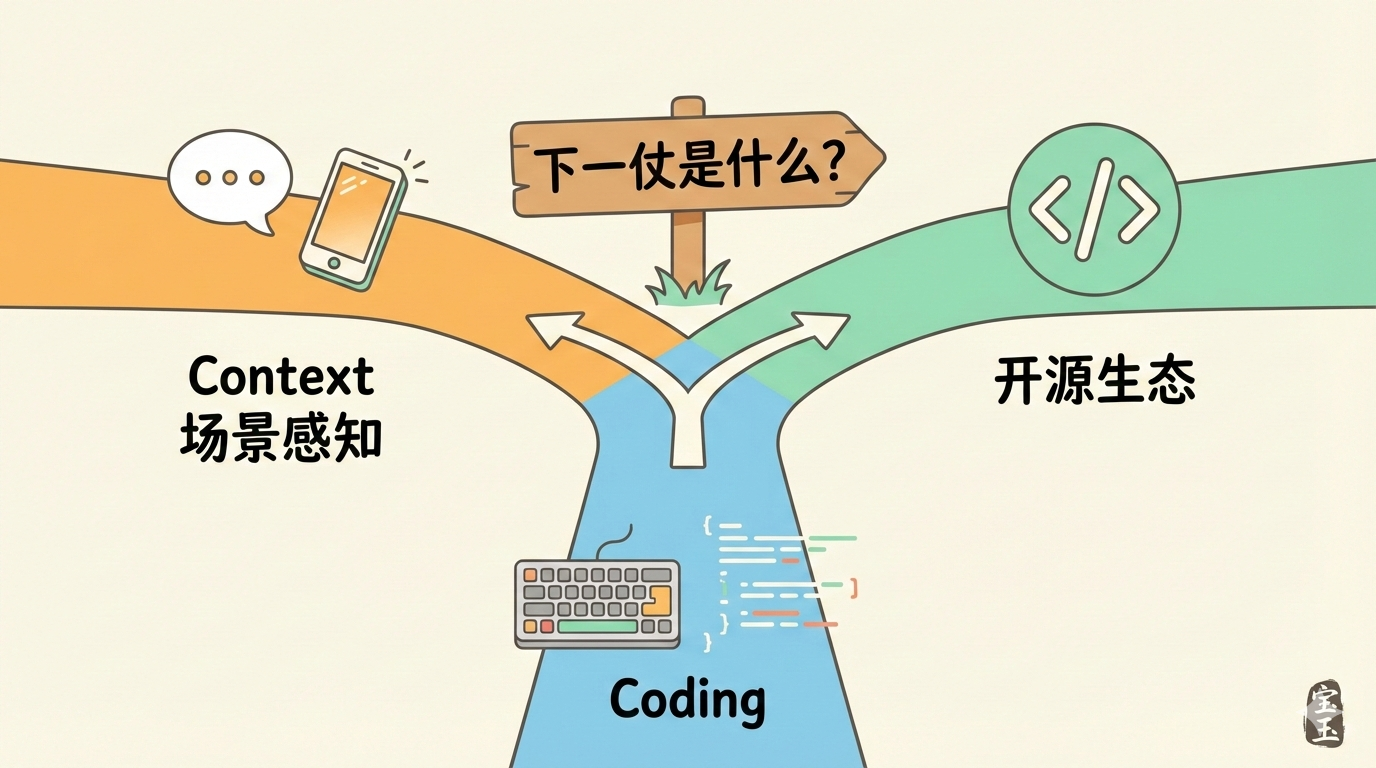
下一个范式在哪?
李广密接着问了个我最关心的问题:
“预训练走了三年,强化学习成为共识,下一个范式是什么?”
姚顺雨说了两点:
“第一,自主学习不是一个方法论,而是数据或者任务。”
每个人对它的定义都不一样。在聊天中越来越个性化是一种自主学习,写代码时越来越熟悉你的环境是一种自主学习,像博士一样探索新科学也是一种自主学习。
“第二,这个事情其实已经在发生了。”
他举例说 Cursor 每几个小时都会用最新的用户数据去学习,Claude 已经写了它自己 95% 的代码。大家觉得没那么震撼,是因为这些公司预训练能力还不如 OpenAI。
但他说最大的问题不是技术,是想象力。
“我们很容易想象强化学习实现后是什么样,比如 O1 在数学题上从 10 分变成 80 分。但如果 2027 年有人宣布实现了自我学习,它应该长什么样?我们还不知道。是一个赚钱的交易系统,还是解决了人类之前没法解决的科学问题?”
李广密追问:如果 2027 年有新范式出来,哪家公司最可能?
“可能 OpenAI 的概率还是更大。它商业化等各种变化削弱了创新基因,但还是最有可能诞生新范式的地方。”
林俊旸先泼了点冷水:
“如果从更实际来讲,RL 的潜力还没有打出来,全球范围内类似的问题还存在。”
然后补充说道:
“今天拿我们自己献丑,我们自己的 Memory 看起来知道我过去干了什么,但只是记起来过去的事情,每次叫一遍我的名字,其实并不显得你很聪明。”
他觉得 Memory 可能还需要一年左右发展。“大家比较卷,每天有新东西,但技术在线性发展。我们每天看自己做的事情觉得真的挺土的,那些 Bug 真的不好意思拿出来跟大家讲。”
杨强从学术视角提到了哥德尔不完备定理:一个大模型不能自证清白,必定有一些幻觉不可能消灭掉。他还用睡眠打了个比喻——人类每天晚上睡觉是在清理噪音,所以第二天能继续学习而不会变笨。
“像这些理论研究孕育着一种新的计算模式。”
唐杰表达了乐观:
“我对 2026 年会有范式革新有信心。”
他说,大模型投入已经巨大,但效率并不高。数据从 2025 年初的 10TB 涨到现在 30TB,未来可能 100TB。但规模扩张带来的收益,和高昂的计算成本不成正比。
花 10 亿、20 亿,回报可能微薄。
这不是 Scaling 没用了。Scaling 肯定能提升智能上限。问题是性价比。
唐杰提出了一个新指标:Intelligence Efficiency,智能效率。用更少的投入,获得更大的智能增量。
当 Scaling 收益递减,提升效率就成了核心竞争力。这会倒逼新范式的诞生——不是因为老办法不行,而是老办法太贵。
有个有意思的变化:学术界的机会来了。
两年前,工业界有上万片算力卡,高校可能只有 1 片。差距是万倍。但到 2025 年底,很多高校已经配备了充足算力,差距缩到 10 倍。创新的种子开始孵化。
四个人对“范式”的理解完全不同:
-
• 姚顺雨说想象力是瓶颈
-
• 林俊旸说技术还早期
-
• 杨强说理论需要突破
-
• 唐杰说效率是核心
Agent 四阶段
话题转到 Agent。李广密说,有人预期 2026 年 Agent 可以在后台推理 3-5 小时,做人类一两周的工作量。
杨强给 Agent 画了一张演进路线图,很简洁。
目标谁定义?规划谁定义? 这两个问题排列组合,就是四个阶段:
-
• 阶段 1:目标人定义,规划人定义。这是现在。你得告诉 AI 做什么、怎么做。
-
• 阶段 2:目标人定义,规划 AI 定义。你只说目标,AI 自己找路径。
-
• 阶段 3:目标 AI 定义,规划人定义。AI 观察你的需求,自己提出该做什么,你来定怎么做。
-
• 阶段 4:目标 AI 定义,规划 AI 定义。终局。大模型内生地定义目标和规划。
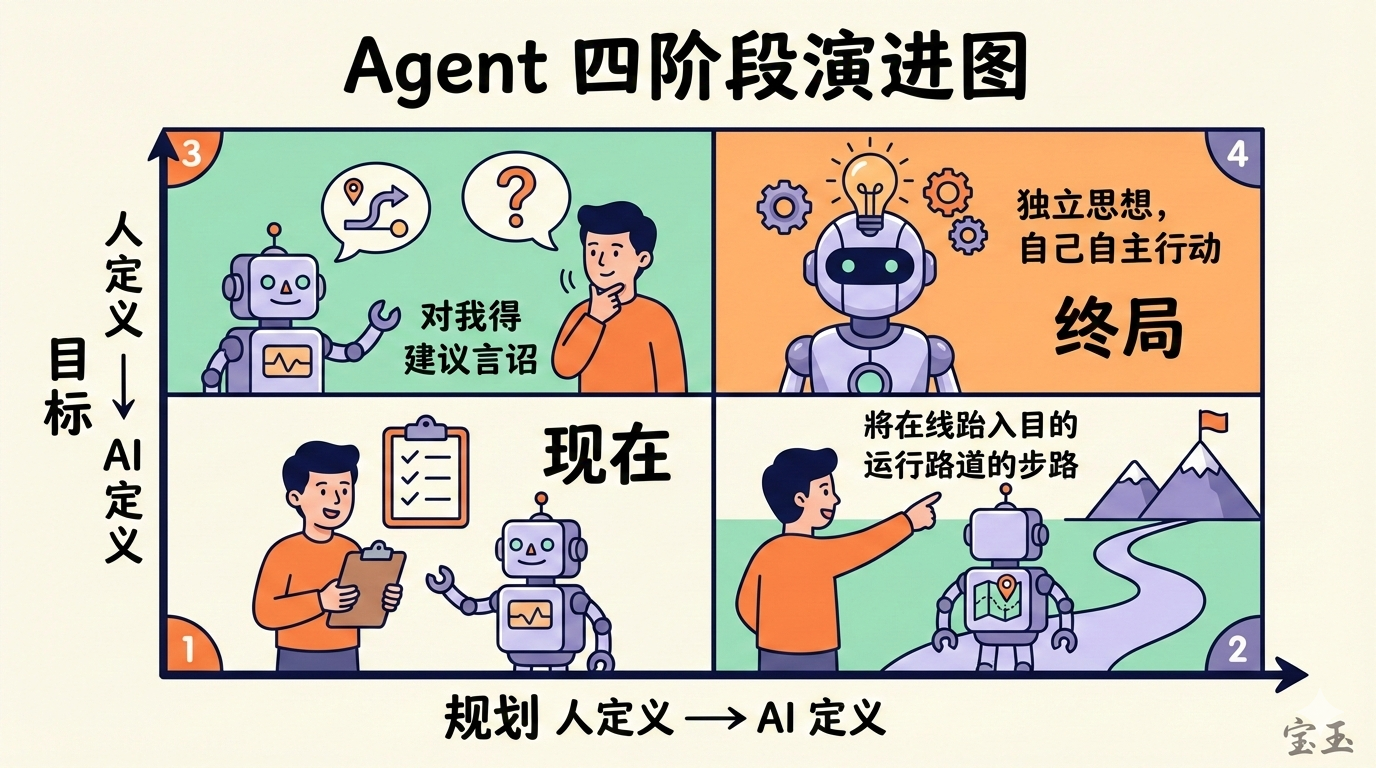
杨强说,我们现在处于非常初级的阶段。但未来会出现原生系统——大模型观察人类工作,自主利用数据,内生地定义目标和路径。
林俊旸补充了一个角度:
“通用 Agent 的核心能力,是解决长尾问题。”
头部需求容易满足。难的是长尾——用户“到处找不到答案”的那些问题。AGI 的魅力,就在于能解决别人解决不了的事。
模型即产品
李广密问了一个争议已久的问题:
“通用 Agent 这个机会是创业者的还是模型公司的?”
林俊旸说:
“见仁见智。如果创业者是套壳高手,套得可以比模型公司做得更好,我觉得可以去做。但如果你没有这个信心,这个事情可能是留给模型公司的。因为他们遇到问题的时候,只要训一训模型、烧一烧卡,这个问题可能就解决了。”
他补充了 Agent 真正的价值:
“今天 AGI 最大的魅力是在长尾。一个用户真的寻遍各处都找不到能帮他解决问题的,但是在那一刻,我感受到了 AI 的能力——全世界任何一个角落寻遍各处都找不到,但你却能帮我解决。”
套壳的护城河很浅。
唐杰补充了三个决定 Agent 命运的因素:价值、成本、速度。
这个 Agent 解决的问题有多大价值?成本是不是太高?做应用的速度够不够快?
如果调一个 API 就能解决问题,但 Agent 成本特别大,那就是矛盾。如果你有半年的时间窗口能迅速把应用做出来,那就有机会。但一旦模型公司反应过来,窗口就关了。
一个应用层的东西如果价值很大,模型公司就会把它做进基座。
模型公司和创业者的博弈,谁赢真不好说。但林俊旸的“见仁见智”背后,其实是在说:如果你没有独特的数据或场景壁垒,套壳创业很危险。
我觉得如果你正在做“套壳”类产品,也不要就被大佬们劝退了,问题不是“套壳有没有戏”,而是“你套的壳能不能建立独特价值”。如果只是简单调用 API 做个界面,确实没戏。但如果你在某个垂直场景里,有独特的数据、独特的用户、独特的工作流理解,那这个“壳”可能比底层模型更值钱。
模型公司愿意做所有事吗?未必。能做所有事做好吗?更不一定。大模型时代拼的是速度和时间。
中国 AI 公司成为全球领先者的概率有多大
李广密问:
“3 到 5 年后,全球最领先的 AI 公司是中国公司的概率有多大?”
林俊旸第一个回答:
“我觉得是 20% 吧,20% 已经非常乐观了,因为真的有很多历史积淀的原因在这里。”
他解释了差距在哪:
“美国的 Compute 可能整体比我们大 1-2 个数量级。但我看到不管是 OpenAI 还是什么,他们大量的 Compute 投入到的是下一代的 Research 当中去。我们今天相对来说捉襟见肘,光交付可能就已经占据了我们绝大部分的 Compute。”
人家有钱探索,我们只够干活。

但他也说了希望:
“穷则思变。我们虽然是一群穷人,是不是穷则思变,创新的机会会不会发生在这里?”
他提到团队里的 90 后、00 后冒险精神越来越强。“概率没那么大,但真的有可能。”
姚顺雨相对乐观一些:
“概率还挺高的。任何一个事情一旦被发现,在中国就能够很快复现,在很多局部做得更好。”
但他也指出了核心问题:
“中国想要突破新范式或者做非常冒险事情的人可能还不够多。我们太爱确定性了。一个事情只要被证明能做出来,我们都很有信心几个月就搞清楚。但如果让一个人说探索持续学习这种不知道能不能做起来的事情,就比较困难了。”
他的判断是:
“能不能引领新范式,可能是今天中国唯一要解决的问题。因为其他所有事情,无论是商业还是工程,我们某种程度上已经比美国做得更好。”
唐杰的回答最有情怀。他先开了个玩笑:
“我们这一代最不幸运,上一代还在工作,下一代已经出来了,把我们无缝跳过了。”
然后正色说:
“中国的机会是一群聪明人真的敢做特别冒险的事。现在的 90 后、00 后是有这个劲的。如果我们笨笨的坚持,也许走到最后的就是我们。”
笨笨的坚持,也许走到最后的就是我们。
最后
如果说简要总结一下:
-
• 姚顺雨说 Context 比 Intelligence 重要
-
• 林俊旸说光交付就占了绝大部分算力
-
• 唐杰说 Intelligence Efficiency 倒逼新范式
-
• 杨强说理论突破孕育着新计算模式,Agent 四阶段描绘了演进路线
模型即产品意味着套壳创业壁垒很薄。
大模型时代拼的是速度和时间。
笨笨的坚持,也许走到最后的就是我们。
